Abstract
Imagine that a biologist arrived at your big family reunion and had no idea who were sisters, cousins, aunts, uncles, etc., but tried to sort it out by how all of you look. Just based on how you look, would s/he be able to guess whether the kid standing next to you is your sister or your cousin? The biologist might be able to make some good guesses this way, but by using samples of your family's DNA, s/he could construct your whole family tree. In this project, you'll use Web-based computer programs and some background research to make your own evolutionary tree for a group of your choice. (For a more basic project, see The Tree of Life — I (basic)Summary
Edits: Svenja Lohner, PhD, Science Buddies
Sponsor: Molecular Sciences Institute (MSI), Berkeley, California
Management: The Kenneth Lafferty Hess Family Charitable Foundation
Objective
The goal of this science project is to compare a protein's amino acid sequence in a couple of animals to infer how closely related they are to one another. You have access to the same online genomics databases and software that scientists use every day. You can select a few animals you are interested in and find a protein common to all of them using information you can find online. Then you can use an online software tool to line those proteins up and compare the sequences. The more similar the amino acid sequence of the protein, the more closely related the two species are! In doing this project, you will learn about making use of the tremendous amounts of DNA and protein sequence data that is available online and using publicly available software to analyze and study these sequences. You will also learn about using DNA or protein sequences to understand evolution and how different organisms are related to one another.Introduction
Think about or draw out your family tree adding aunts, uncles, and cousins. The tree could look like the tree in Figure 1 (except that you would fill in the names of your relatives.) If you don't have siblings or cousins just draw a big family tree from your imagination. Based on your family tree, you can see that you are more closely related to your sister (or brother) than you are to your cousin; that is there are fewer "branches" separating you from your sister than there are separating you and your cousin.
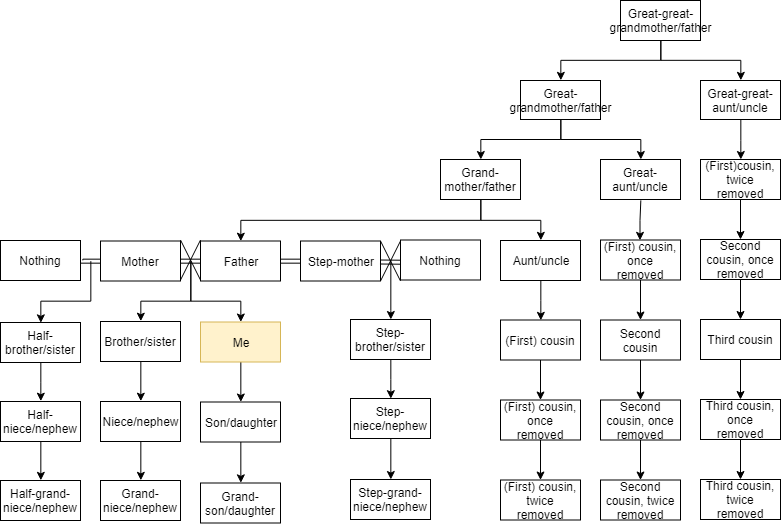 Image Credit: Wikimedia Commons, Olegispe / Creative Commons Attribution-Share Alike 4.0 International lic
Image Credit: Wikimedia Commons, Olegispe / Creative Commons Attribution-Share Alike 4.0 International lic
Figure 1. Example family tree. (Wikimedia, Author Olegispe, CC BY-SA)
Now imagine that a biologist arrived at a big family reunion and had no idea who were sisters, cousins, aunts, uncles, etc. but tried to sort it out by how all of you look. Just based on how you look, would s/he be able to guess which of the two kids standing next to you is your sister and which is your cousin? In many families, the biologist may be able to make a pretty good guess based on your visible features (called your morphology), like number of arms/legs/eyes, hair color, nose shape, etc. (Notice that some of these morphological features are shared by all humans but that other features can be used to distinguish you from one another.) But this is not a fail-safe approach to determining familial relationships—as some people look more like their cousin than their sister, right? You could just use morphology to make a good guess.
So what is the best way to determine how related you are to one another (besides just asking -- but stick with me here)? The biologist would have to look at your DNA! You get half of your DNA from your mother and half from your father. Both of those "halves" are very similar to one another—with one difference about every 1000 base pairs (but out of three billion total letters—that's three million differences!). And your mother and father got their DNA from their parents and so on up the family tree. Your DNA should be MUCH more similar to your sister's than your cousin's because you and your sister both got your DNA from the same parents, whereas there are many more branches in the tree (and thus many more matings and DNA base pair differences entering the tree) between you and your cousin. That is, you are much more similar genetically to your sister because you have more recent common ancestors than you and your cousin.
Family Trees In Biology
So how does all of this apply to biology? For centuries, scientists have been trying to draw the family tree that reflects the history and evolution of all animals on the earth. This tree would show which species are more closely related to one another, like the case where you are "closer" to your sister on your family tree than you are to your cousin. For example, humans are more closely related to chimpanzees than to dolphins, so chimps and humans would have fewer branches between them on the "animal family tree."
How do scientists make this family tree? For many years, scientists relied on comparisons of morphological characteristics (like hair, teeth, limbs, fins, hearts, livers, eyes, etc.) to try to figure out who was more closely related to whom. These kinds of comparisons are often accurate, but as you saw in the example of a human family, these physical characteristics can sometimes be misleading. Evidence of this concept is that different scientists would come up with different trees/relationships by using different sets of morphological information! So which tree is "right?"
To think about how to identify the "right" tree, we have to think about how these animals became different from one another throughout evolution. All heritable morphological changes (those changes that can be passed down to the next generation) are a result of changes (mutations) in an organism's DNA. This mutation can lead to a change in a protein sequence or a change in when, where or how much of the protein gets made. That's it! One or a couple of these changes can lead to big a difference in morphology and/or the way a single cell in the organism can function. So over billions of years of evolution, a slow accumulation of DNA sequence (and thus some protein sequence) changes has led to the existence of all of the earth's different species—with some more closely related to one another than others. This whole process is called molecular evolution.
So, as we saw with the family reunion example, the best way to see how related two organisms are is to compare their DNA or protein sequences. (Remember that a protein's sequence is encoded in its gene's DNA - so the only way to get a protein sequence change is to get a change in the DNA that codes for it.) Those organisms with the most similar DNA/protein sequence are almost surely more closely related than those with less similar DNA/protein sequences.
Why didn't scientists use DNA sequences to build the trees 100 years ago? First, it has only been about 50 years since the discovery that DNA is actually the genetic material that gets passed on through generations. Second, DNA and protein sequencing technologies have only recently gotten efficient enough that DNA/protein sequence data is available from many different kinds of animals. With all of this new information, scientists are working hard to build the "true" animal family tree. And there have been cases where the tree built using DNA sequence data differs from those built using morphological data! (Can you explain for your project why DNA sequence is the "gold standard" for determining relatedness between animals?)
Note: Even though sequence comparison is the gold standard, it is not perfect. Sometimes comparisons of different proteins will yield different trees. Which one is right? Why might this happen?
Your Project
Your goal in this project is to locate an "old" evolutionary tree (what we've been calling the animal family tree) that was built based on morphological (or non-DNA sequence based) data. You may be able to find this kind of tree in an older biology textbook or possibly online. You can then use this tree to form a hypothesis about what you expect to find if you compare a particular protein's sequence between some species on the tree. Do you think you will confirm the relationships/relatedness implied by the old tree or do you think the sequence-based comparison will yield different relationships? Why did you form this hypothesis? (A really good project would follow this protocol for at least a few different proteins and see if you get the same results for each.)
First, you can find a protein in humans that interests you. (It is a little simpler to do protein comparisons for tree building than DNA sequences, but you are welcome to try either one.) Then you can go to a public database called "Genbank" where scientists from all over the world deposit DNA and protein sequences that they discover. From Genbank, you can find the human sequence of the protein you have chosen. Next, you can ask a computer program called BLAST to search all of the protein sequence databases available to find the most similar protein sequence in other organisms (the same gene or protein found in a different species is called a homolog). Finally, you can compare the amino acid sequences of the protein from the different species you found to draw your own version of the animal family tree (containing only the animals used in your study). This comparison is done by making an "alignment" of all of the proteins you are comparing and then "counting" the differences. Do the relationships shown in your tree agree with where your animals appear on the old tree? Can you think of an explanation for whatever outcome you get?
Keys:
- Start with lots of proteins of interest. You will need to be able to locate protein sequence information from multiple other species (this is not available for all proteins!).
- Most of the databases are very "messy" and hard to sort through. Thus, it is hard to be sure you have found exactly what you are looking for. Ask your advisor to check with you! The same is true for many of the online analysis tools.
- Since most of your "experiments" are done on the computer with computational tools found at biology related websites, it is VERY important that you understand (at least in very general terms) WHAT the programs do and what you learn from using them.
Terms and Concepts
- DNA, gene
- mRNA
- Amino acid, protein sequence
- Protein, translation
- Coding sequence
- Sequence/protein/molecular evolution
- Homolog/homology
- Sequence alignment, distance matrix
- Eukaryote, prokaryote
- Phylogenetic/evolutionary tree
Bibliography
- NIH. (n.d.). About Genomics. National Human Genome Research Institute. Retrieved September 2, 2021.
- Cold Spring Harbor. (n.d.). DNA Learning Center. Retrieved September 2, 2021.
- Evolution Lesson in the archived ENSIWEB site: https://ensiweb.bio.indiana.edu/lessons/index.html. Retrieved September 2, 2021.
- PBS. (n.d.). Evolution. Retrieved September 2, 2021.
- Access Excellence. (n.d.). Activities Exchange - Evolution. The National Health Museum. Retrieved September 2, 2021.
Choosing a gene/protein to study
- Popular science/media stories
- NCBI. (n.d.). OMIM. Online Mendelian Inheritance in Man. Retrieved September 2, 2021.
- NIH. (n.d.). PubMed (searchable database of scientific journal articles). National Library of Medicine. Retrieved September 2, 2021.
Finding the DNA/mRNA/protein sequence for that gene
- NCBI. (n.d.). Welcome to NCBI. National Center for Biotechnology Information.
Retrieved September 2, 2021.
- Can access OMIM, BLAST, GenBank, PubMed from here and search databases of protein and DNA sequences.
Finding homologs in other species
- NCBI. (n.d.). BLAST. National Center for Biotechnology Information. Retrieved September 2, 2021.
- NCBI. (n.d.). COG. National Center for Biotechnology Information. Retrieved September 2, 2021.
- NCBI. (n.d.). BLAST Tutorial. National Center for Biotechnology Information. Retrieved September 2, 2021.
Multiple sequence (DNA/RNA/protein) alignment tools
- EMBL-EBI. (n.d.). T-Coffee. Retrieved September 2, 2021.
- Has useful colored output (click "html" under Scores column of results page). Note that sequences must be in FASTA format (see help file).
- EMBL-EBI. (n.d.). ClustalW2. Retrieved September 2, 2021.
- Don't worry about all the optional parameters -- simply paste in all of your sequences in FASTA format.
General DNA/Protein analysis tools
- NCBI. (n.d.). Welcome to NCBI. National Center for Biotechnology Information. Retrieved September 2, 2021.
- SIB. (n.d.). Expasy. Swiss Institute of Bioinformatics. Retrieved September 2, 2021.
- Los Alamos National Library. (January 20, 2016). Neighbor Treemaker. Retrieved September 2, 2021.
- Example of tree building software.
Tutorial on which this idea is based:
- University of Wisconsin. (2002). Generation of Phylogenetic Tree based upon DNA sequence analysis. Comparing primate proteins. Retrieved September 2, 2021.
Materials and Equipment
- Computer with Internet access
- Lab notebook
Experimental Procedure
- Locate an "old" evolutionary tree—that is one that was created without the help of molecular biology. (A pre-1995 text book is one good place to find a non-molecular biology evolutionary tree.) Generate a hypothesis for whether or not you think the tree built by protein sequence comparison will match those relationships outlined in this "old" tree. Why did you generate this hypothesis? Back up your reasoning!
- Identify a few genes/proteins of interest. You may choose a gene/protein you heard about through a major media source like the news or a magazine. One other good resource is a database called "Online Mendelian Inheritance in Man" (OMIM) which catalogs all known human genetic diseases and which genes may be involved in causing or creating susceptibility to that disease (if that information is known). You can also try to use "PubMed" which is a searchable database of scientific journal articles on as many topics as you can think of, but these articles are usually pretty dense and tough to read—but you can learn a lot from reading the abstracts available for every paper. Remember to choose a few as not all proteins are found in all species, nor is sequence data available for all of the species that have that protein. Also, think about which "type" of protein you are choosing. See variations discussion for more thoughts on choosing a "type" of protein.
- Go to the NCBI website and search the "protein" category for the name of the protein you have chosen. Notice that sometimes it may be listed under an abbreviation or slightly different spelling, so just keep trying variations until you get it. (If you can not find it using the protein search, you can try searching for the gene's name in the "nucleotide" search category. That listing will often show the protein sequence as well.) Get the protein's amino acid sequence data from NCBI/Genbank. Get help from your advisor making sure you've got the "whole protein" as you will probably get more than one "hit" when you do your search. And, be sure to document the accession number of each protein you select. (See definition of accession number.)
Tips for Searching Genbank
- For making a better query, try asking for both the name of the protein and the organism from which you would like that sequence. (For example, try entering "myoglobin homo sapiens" to look for the human version of the myoglobin protein sequence.)
- When sorting through the results, many entry titles are followed by two Latin words in parentheses such as (Homo sapiens). These words represent the scientific name of the animal from which the sequence came.
- Some animals are used very often in genetic research and are called "model organisms." You are very likely to run across sequences from these organisms. See below for a table of some of the commonly used model organisms and their scientific names.
| Common Name | Scientific Name |
|---|---|
| Human | Homo sapiens |
| Mouse | Mus musculus |
| Rat | Rattus norvegicus |
| Zebra Fish | Danio rerio |
| Fruit Fly | Drosophila melanogaster |
| Round Worm | Caenorhabditis elegans |
| Yeast | Saccharomyces cerevisiae |
The genomes of many other animals are being sequenced (mainly) for sequence comparison studies such as the one you are performing. Here are a few of these types of organisms you might run across. If the name you find is not on this list, just do a web search and see if you can figure out to which animal the name refers!
| Common Name | Scientific Name |
|---|---|
| Chimpanzee | Pan troglodytes |
| Baboon | Papio anubis |
| Rhesus Monkey | Macaca mulatta |
| Cow | Bos taurus |
| Dog | Canis familiaris |
| Cat | Felis catus |
| Opossum (laboratory) | Monodelphis domestica |
| Pig | Sus scrofa |
| Chicken | Gallus gallus |
| Frogs | Xenopus laevis and Xenopus (Silurana) tropicalis |
| Puffer Fish | Takifugu rubripes |
| Purple Sea Urchin | Strongylocentrotus purpuratus |
| Acorn Worm | Saccoglossus kowalevskii |
| Honey Bee | Apis mellifera |
- These queries are very literal and just look for your search words anywhere in the title or description of the sequence. So if you enter "myoglobin," you may get a hit to a protein described as a "myoglobin binding protein" or "similar to myoglobin," neither of which is what you are looking for. You can get around this by using the "Advanced" search option: Click on the word "Advanced" below the text box where you enter your gene or protein name. In the new window, go to the pull down menu that says "All Fields" and change it to "Title." This way, your search term has to appear in the title of the database entry. You still may get multiple hits, so just keep scrolling through the results until you find the myoglobin protein itself.
- Some sequence entries represent fragments or pieces of a protein that have been important for one experiment or another. For this project, you need the whole sequence, so try to avoid using sequences that have the words partial, chain or subunit in them. If all of the entries seem to be incomplete, you may need to choose a different protein.
- Note: If you are doing a project that involves searching for DNA/mRNA sequences, some entries will be marked as either "partial cds" or "complete cds," where cds stands for "coding sequence." You should choose "complete cds" if such an entry can be found for your gene—remember this point applies only to DNA/mRNA searches.
- Finally, what is the best way to refer to the "right" sequence when you find it? The first string of letters/numbers in the output of any search on NCBI is called the accession number. This may look something like NP_00555 or AAH14547. This is just a unique identifier for that sequence file in that database. So you could tell anyone else in the world you are using the sequence from accession number NP_00555 and they would be able to access the exact same record. If you want to get back to that file, you can just enter that accession number for your query and the proper file should come up every time.
- One other thing you might run in to is cDNA. What is a cDNA? A cDNA is just the sequence of a DNA string that would be COMPLEMENTARY (thus the "c") to an mRNA of interest. (RNA molecules are inherently unstable, so scientists often make a DNA copy of an RNA to make experiments easier.) So a cDNA sequence represents an mRNA found in a cell.
Tips for Formatting Sequences
- Are you looking at DNA or protein sequence? If the string of letters in your sequence is made up of a, t, g and c, then you are looking at a DNA or RNA sequence. If the string looks like "random" letters from the alphabet (like MQPLLG), then you are looking at a protein sequence. Each amino acid has been assigned a single letter code to represent it. (You can find this code online or in a textbook.)
- When copying your sequence of interest to save it or enter it into another program, there are a couple of ways you can do it. Whichever way you choose, it is probably easiest to "store" and manipulate the sequence in a word processing program. You can then save it as a "text" file so that it doesn't have any weird word processing formatting. (You may also be able to upload a text file into a DNA analysis program.)
- The first way to save the sequence is just using the string of sequence alone. From the accession number file, you can just copy and paste the letters onto a word processing document. Then just take out any of the numbers that were copied over. You do not need to worry about spaces and returns because the programs you will be using are trained to ignore them and only read the "letters" in the file. Then, you can just copy and paste this saved text into the program you are using.
- Most programs that analyze DNA/mRNA/protein sequences require them to be in a certain format. Thus, when you are saving the sequences that you plan to use in your later analysis, you should save them in the conventional format. The most common format is called "FASTA" format. FASTA files are structured with the ">" symbol followed by the name of the sequence (like myoglobin), then a return and the text of the sequence. Most of the programs you use will recognize a FASTA file and know that what comes after the > and before the first return is the "name" of the sequence. Here is an example of a FASTA format sequence:
>Myoglobin protein mglsdgewql vlnvwgkvea dipghgqevl irlfkghpet lekfdkfkhl ksedemkase dlkkhgatvl talggilkkk ghheaeikpl aqshatkhki pvkylefise ciiqvlqskh pgdfgadaqg amnkalelfr kdmasnykel gfqg
- The simplest way to get your sequence into FASTA format is to use the FASTA format display option in Genbank. Once you are on the page containing the DNA or protein sequence that you want, you can get your sequence into this format by clicking on the "FASTA" link below the "NCBI Reference Sequence" information. You can then either cut and paste the formatted sequence into a text file, or use the pull down menu next to the "Send To" button and change it to "File." If you then click on the button, it will download the sequence on your screen to the file name you specify.
- Note that you don't need to worry about spaces and returns in most sequence analysis programs because they ignore them and only read the "letters" in the file.
- Use the BLAST program (at NCBI or elsewhere) to search the non-redundant (nr) database of proteins (Protein BLAST or BLAST-P) for homologs from other species. All BLAST does is search all available databases for other proteins that are the most similar to the one you entered. It then gives you an output with "matching" sequences ranked by which is the most similar to the one you entered. Be sure to check the alignment on the BLAST readout to make sure the two sequence do not just share a small stretch of similarity, but look to actually be from homologous proteins. You should try to find your gene in at least 3 or 4 other organisms in order to construct a meaningful sequence alignment. (Note: Some programs "max out" if you try to put in too many sequences at one time, so you may have to do them in batches.)
- Use a multiple sequence alignment program (like CLUSTAL W from Expasy or other sources) to do a "multiple sequence alignment" to compare sequences from multiple species. Your input file should be a list of FASTA formatted sequences representing the same gene in different organisms. All this kind of program does is line up the proteins (using their most similar regions) so that you can tally up the differences in the sequences.
- Use the alignment program (or any other tree-building program) to generate a distance matrix or a tree. A distance matrix just assigns a "distance value" (which is a reflection of how related the two sequences are based on "counting" differences in the alignment) to each pair of sequences you entered. That is, those animals with a higher "distance value" are less closely related than those with a lower "distance value." Use the distance matrix you generated to build a tree yourself. Or you can enter the sequences into an alignment program that will build the tree for you.
- Note: This "counting" is not purely counting differences, but weights different changes with different values based on how rare or common that kind of change is, etc. So it is a little bit more sophisticated than just counting differences. That is why it is great to have a computer program to help you out!
- How does this data support or disprove your hypothesis? Possible explanations?
Ask an Expert
Global Connections
The United Nations Sustainable Development Goals (UNSDGs) are a blueprint to achieve a better and more sustainable future for all.

Variations
- You may want to explore using different "types" of proteins and thus different "parts" of the evolutionary tree for this study. That is, some gene/protein types are found in almost all living eukaryotes (what does this mean?), such as a protein involved in respiration or glycolysis. Therefore, you could get the protein sequence for a glycolysis gene from animals across the animal kingdom from yeast to humans. On the other hand, a protein involved in red blood cell function (like hemoglobin) will probably only be found in animals with red blood cells; therefore, a comparison across the whole animal kingdom would be unsuccessful. Both types of studies are equally valuable, and maybe you could choose a couple of each type of protein.
- Which species are "good" for which types of comparisons? That is, which species would be good to use if you were studying the evolution of proteins involved in the development of a spinal cord?
- You can use mRNA and/or DNA sequences to ask similar questions.
Careers
If you like this project, you might enjoy exploring these related careers:







{kind=link}