Drugs & Genetics: Why Do Some People Respond to Drugs Differently than Others?
Abstract
In a survey conducted from 2007 to 2010, the U.S. Centers for Disease Control and Prevention reported that about 49% of people in the United States had taken at least one prescription drug during the past month, and about 22% of people had taken three or more prescription drugs. People are prescribed drugs all the time, but prescriptions can be dangerous because people can have different responses to drugs. These responses largely have to do with genetic mutations. Why are some genetic mutations associated with a different response to a drug? In this science project, you will explore an online drug and genetics database to identify how a genetic mutation can be associated with how a person's body processes, and responds to, a certain drug.
Summary
Basic understanding of what genes, DNA, and proteins are.
Readily available
No issues
Edited by Svenja Lohner, PhD, Science Buddies
/-/https/www.sciencebuddies.org/cdn/Files/12111/12/dna-helix-protein-thumbnail.jpg)
Objective
Determine why some gene mutations cause people to respond differently to a drug.
Introduction
/-/https/www.sciencebuddies.org/cdn/Files/12111/12/dna-helix-protein-thumbnail.jpg)
In a survey conducted from 2007 to 2010, the U.S. Centers for Disease Control and Prevention reported that about 49% of people in the United States had taken at least one prescription drug during the past month, and about 22% of people had taken three or more prescription drugs. This was a significant increase from the percentage of people taking prescription drugs just over a decade earlier. Prescription drugs serve important medical purposes, such as helping to prevent heart attacks or treat different cancers, but taking drugs can sometimes be dangerous because different people can respond differently to drugs.
These different responses largely have to do with differences in genetics. Every person has a genome (all of the DNA in an organism) with 20,000 to 25,000 genes, and each gene contains hundreds to millions of DNA nucleotides. People can have a single DNA mutation (change in the DNA sequence) that is associated with an increased, or decreased, response to a certain drug. But it depends on what, and where, the mutation is.
Every gene in the human body consists of DNA (deoxyribonucleic acid). DNA is a genetic code that is made up of four different types of nucleotides: adenine (A), thymine (T), guanine (G), and cytosine (C). This DNA code is turned into mRNA (messenger ribonucleic acid) in our bodies in a process called transcription. In mRNA, a nucleotide called uracil substitutes for every thymine. But transcription is a bit more complicated than that. In transcription, DNA is initially turned into pre-mRNA, and in order to turn this into the final mRNA code, a process called splicing removes certain pieces of the pre-mRNA. Specifically, splicing removes pieces called introns, while other pieces called exons are left in and reassembled, becoming part of the final mRNA code.
The mRNA then goes through a process called translation to turn into amino acids. During translation, every three mRNA nucleotides code for a single amino acid. This set of three nucleotides is called a "codon," and different codons may code for the same amino acid. In the end, a sequence of DNA has been turned into a sequence of amino acids joined together in a long chain, which is called a protein. A protein has the same name as the gene that encodes for it, except that gene names are italicized and protein names are not. Proteins are responsible for most of the functions of our cells.
While introns are labeled "non-coding DNA" because they do not ultimately code for a protein (since they are removed in transcription), they are still very important for the generation of a functional protein. Inside the introns, there are instructions for how the pre-mRNA should be processed into mRNA for a given gene. To further complicate things, multiple genes may rely on the same DNA space. For example, an intron in one gene may be part of an exon in another gene. Consequently, a mutation in one gene may affect a gene nearby it. Additionally, introns are not the only "non-coding DNA." Adjacent to where the exons in a gene start and end are DNA regions called untranslated regions (UTR). As their name implies, these sequences are not translated into amino acids, but still have important instructions for how to process the mRNA.
Because of these processes, a mutation in one DNA nucleotide (which is called a SNP, for single-nucleotide polymorphism) can prevent a gene from turning into a protein or create a non-functional protein. (Alternative forms of a gene that occur through mutation of the DNA are called alleles.) In a gene's exon, if a single DNA nucleotide is mutated, for example from an adenine (A) to a guanine (G), this may cause the wrong amino acid to be made, and the resulting protein may not work. This is because different amino acids are different in many ways, such as size and in the electric charges they have. These different characteristics affect how they interact with each other as well as the other molecules that surround them (such as other amino acids and water). For example, positively and negatively charged molecules prefer to interact with each other and with water, which is called being hydrophilic, whereas nonpolar molecules do not like to interact with charged molecules or with water, which is called being hydrophobic. These seemingly small differences can have very large consequences, such as how we respond to a prescription drug.
Prescription drugs interact with signaling pathways (biochemical pathways) in our bodies in very specific ways. Signaling pathways involve many different proteins, all affecting each other in a controlled, specific manner, to have far-reaching effects on our bodies as a whole. If the protein that the drug interacts with has been mutated in such a way that the drug cannot interact with it or if the protein is not being made at all, the drug may not function as it should. For example, the drug clopidogrel (also known as Plavix) is used to prevent blood clots. The structure of clopidogrel is shown in Figures 1 and 2. In order for clopidogrel to prevent blood clots, the intestine must first absorb the drug. Then, clopidogrel must become active in the liver by interacting with a series of proteins. Finally it must bind platelets, which are important in forming blood clots. If anywhere in this process a protein is not functioning normally, clopidogrel may not have its desired effect. For example, some individuals have a mutated form of the protein (called ABCB1) that clopidogrel initially interacts with in the intestines, and this may influence how these individuals absorb the drug.
/-/https/www.sciencebuddies.org/cdn/Files/4225/10/BioMed_img001.jpg)
Figure 1. The drug clopidogrel is a small molecule that interacts with signaling pathways in our body in specific ways to prevent blood clots. Mutations in the proteins in the pathways involved can affect how a person responds to the drug.
/-/https/www.sciencebuddies.org/cdn/Files/4226/10/BioMed_img002.jpg)
Figure 2. This is a space-filling model of the drug clopidogrel, the basic chemical structure for which is shown in Figure 1. In the model shown here, green is chlorine (Cl), red is oxygen (O), blue is nitrogen (N), and yellow is sulfur (S).
Consequently, when pharmaceutical companies develop a new drug, they test it on a large number of people to see whether there is a small percentage, or subpopulation, of individuals that have a different response to the drug than most people do. Companies can then do a genetic screening of known SNPs sprinkled across the genomes of the individuals tested to see whether the subpopulation has a SNP or multiple SNPs that are not present in the genetics of the other individuals. As discussed, the identified SNPs may affect the gene they are in, or be found in the DNA for one gene but actually be important for their role in a nearby gene. It can even be that the SNP is linked to another unknown SNP that changes the function of another gene. Genetic linkage means that the two SNPs are physically so close together on the strand of DNA that they are often inherited together.
Once SNPs are identified that are associated with an abnormal response to the drug, doctors can screen patients for the presence or absence of these alleles so that doctors can know ahead of time how these patients will respond to a given drug. This rapidly growing medical field is called pharmacogenomics.
In this science project, you will choose a drug that interests you and, using an online pharmacogenomics database, you will be able to determine why a genetic mutation is associated with how an individual responds to a drug and how this mutation affects the biological signaling pathway that the drug normally functions through.
Terms and Concepts
- Drugs
- Genome
- Gene
- Nucleotides
- Mutation
- DNA
- mRNA
- Transcription
- Splicing
- Introns
- Exons
- Translation
- Amino acids
- Codon
- Non-coding DNA
- SNP
- Alleles
- Hydrophilic
- Hydrophobic
- Signaling pathways
- Genetic linkage
- Pharmacogenomics
Questions
- How does a gene become a protein?
- In a given gene, what kind of DNA mutation would not change the protein that is made?
- Why is non-coding DNA important?
- What makes some amino acids hydrophobic and others hydrophilic?
- Why is it important for pharmaceutical companies to test new drugs on a large number of people?
Bibliography
To do this science project you will need to use these databases:
- PharmGKB. (n.d.). Pharmacogenomics Knowledge Base. Retrieved September 1, 2011.
- NCBI. (n.d.). dbSNP Short Genetic Variations. Retrieved September 1, 2011.
These resources are a good place to start gathering information about genetics, drugs, and pharmacogenomics:
- University of Utah, Health Sciences. (n.d.). Making SNPs Make Sense. Learn.Genetics. Genetic Science Learning Center. Retrieved September 12, 2017.
- Centers for Disease Control and Prevention. (2011, February 18). FastStats: Therapeutic Drug Use. Retrieved September 1, 2011.
- U.S. National Library of Medicine. (n.d.). National Library of Medicine. Retrieved November 10, 2020.
- Genetics Home Reference. (2011, September 12). How Genes Work. Retrieved August 17, 2011.
- National Cancer Institute at the National Institutes of Health. (2005, January 28). Understanding Cancer Series: Gene Testing. Retrieved August 17, 2011.
- The University of Utah. (n.d.). Learn Genetics. Genetic Science Learning Center. Retrieved August 19, 2011.
Materials and Equipment
- Computer with an internet connection
- Access to the PharmGKB online pharmacogenomics database. For details see the Experimental Procedure tab (in the section titled "Determining How Genetics Change Drug Responses").
- Lab notebook
Experimental Procedure
Determining How Genetics Change Drug Responses
You can choose any common drug to study for this science project. Table 1 lists several drugs for which there is ample data. For the purpose of simplifying the directions, we will use the drug clopidogrel as the example throughout the Experimental Procedure.
| Generic Name | Trade Name | Major Use |
|---|---|---|
| Atorvastatin | Lipitor | Lowers cholesterol |
| Azathioprine | Imuran | Treats rheumatoid arthritis |
| Capecitabine | Xeloda | Treats breast and colorectal cancers |
| Carbamazepine | Tegretol | Treats seizures |
| Celecoxib | Celebrex | Treats arthritis |
| Clopidogrel | Plavix | Prevents blood clots |
| Erlotinib | Tarceva | Treats lung, pancreatic, and other cancers |
| Fluorouracil | Efudex | Treats many types of cancers |
| Gefitinib | Iressa | Treats lung cancer and other cancers |
| Imatinib | Gleevec | Treats many types of cancers |
| Irinotecan | Camptosar | Treats colorectal cancer |
| Mercaptopurine | Purinethol | Treats leukemia |
| Tamoxifen | Nolvadex | Treats and prevents breast cancer |
| Thioguanine | Tabloid | Treats leukemia |
| Warfarin | Coumadin | Prevents blood clots |
- First, go to the PharmGKB Pharmacogenomics Knowledge Base Tutorial and follow the steps through the section titled "How can I look up a drug and find out more information on it?".
- On step 4 of the tutorial section, for clopidogrel and other drugs that you investigate, browse through the information in the "Overview," "PGx Prescribing Info," and "Drug Labels" tab.
- What does the entry on clopidogrel tell you about its medical use? What kind of patients would use clopidogrel? How does the drug function, in general?
- For each drug that you investigate, record in your lab notebook the following information:
- The generic and trade (brand) names of the drug.
- What kind of chemical the drug is, and what other drugs it is related to. You may want to draw its chemical structure.
- What medical condition the drug is used to treat.
- The drug's general effect on the body.
- In the "Overview" tab you should also find information about how the drug functions on a molecular level.
- Continue through the PharmGKB tutorial, following the steps through the section titled "I want to look up a drug and find out why it has different side effects when taken by different people, based on their genetics. How can I do this?"
- For clopidogrel and other drugs that you investigate, when looking at the "Pathways" tab (steps 1 to 3 in the tutorial) look at the graphical representation of the pathway, and read the description of the pathway below the image, paying special attention to descriptions of the different components shown in the image and how they interact with the drug. In the "Overview" tab for clopidogrel there should be a section that discusses the pharmacogenomics of the drug, which is how the alleles (versions) of a gene (or genes) that a person has inherited changes their personal biology in a way that makes a drug more or less effective. Alleles are alternative forms of a gene that occur through mutation of the DNA. In the case of clopidrogel you would want to think about and answer these questions:
- How does clopidogrel interact with P2RY12? What is P2RY12?
- What do CYP1A2, CYP2B6, CYP2C9, CYP2C19, and CYP3A4/5 all have in common?
- What drug-drug interactions is clopidogrel involved in?
- Read about how patients' responses to clopidogrel are variable, paying special attention to the proteins that make the response variable.
- How does ABCB1 interact with clopidogrel?
- If it is discussed for your drug of interest, record the gene name and rsID for gene alleles that are associated with variable response to the drug. In your lab notebook, copy and fill out Table 2 with this information and add additional rows as needed. Table 2 will be discussed in further detail.
- For example, for clopidogrel an allele of the ABCB1 gene with the rsID of rs1045642 can affect absorption of the drug in patients with cardiovascular diseases. For clopidogrel there are other genes and variants discussed as well.
- If there are multiple links to pathways listed in the "Pathways" tab, look at all of them.
- Continue through the tutorial by looking at the "Clinical Annotations" tab (steps 4 to 5), and read over the different alleles that are associated with the pharmacogenomics of clopidogrel and other drugs that you investigate.
- Continue filling out Table 2 in your notebook as you collect more information on your selected alleles.
- Look for alleles of genes that were discussed in the "Overview" tab in the pharmacogenomics section. There may be a lot of alleles listed, and they may not all be of genes that were covered in the "Overview" tab.
- For example, for clopidogrel in the "Clinical Annotations" tab you will find an allele of the CYP2C19 gene. The rsID rs4244285 will be there, and the information listed for this allele should be similar or related to its description you read in the "Overview" tab.
- If the "Overview" tab did not give information on alleles and rsIDs for a drug that you are investigating, when looking at each allele listed in the "Clinical Annotations" tab, pay special attention to the gene name (under "Gene"), the allele's rsID (under "Variant"), the effect of the interaction with the drug (under "Type"), and the phenotypic impact of the variant (under "Phenotype").
- Look at the "Pathways" tab again and locate the allele's gene name. How does the protein that this gene encodes interact with the drug in the pathway?
- How do you think the change in the allele affects how the body responds to the drug?
- To find additional information on the gene alleles that are associated with a varied response to the drug, continue through the tutorial by exploring the information available in the "Related To" tab (steps 6 to 8).
Identifying the Mutations
Once you have the information on a drug of interest and the proteins it interacts with in the body, you can figure out why a simple mutation in the DNA that encodes for this protein is associated with a different response to the drug.
- You should have already copied and started filling out Table 2 in your notebook. Table 2 has been partly filled in with information on alleles of some genes, specifically ABCB1, P2RY12, and CYP2C19, that are associated with a varied response to the drug clopidogrel. In this part of the science project, you will fill in the rest of Table 2 and add additional rows with information on other drugs and alleles.
| Generic Name of the Drug | Protein that has Variable Response to the Drug | How this Protein Interacts with the Drug | rsID of an Identified Allele | Exon, Intron, or Other? | Codon Sequence Change (DNA) | Codon Sequence Change (mRNA) | Amino Acid Sequence Change | Effect |
|---|---|---|---|---|---|---|---|---|
| Clopidogrel | ABCB1 | Involved in the intestinal absorption | rs1045642 | Exon | ATT → ATA | AUU → AUA | I [Ile] → I [Ile] | |
| Clopidogrel | P2RY12 | rs2046934 | Intron | N/A | N/A | N/A | ||
| Clopidogrel | CYP2C19 | rs4244285 | Exon | ATG → GTG | AUG → GUG | M [Met] → V [Val] | Changes from a neutral, nonpolar amino acid to another neutral, nonpolar amino acid. |
- Start by going to the SNP Database: http://www.ncbi.nlm.nih.gov/projects/SNP
- In the search bar at the top of the website, enter an rsID of an allele of interest, as shown in Figure 3, circled in green. For example, for clopidogrel enter rs1045642. Click "Go."
- Remember, you made a list of alleles and rsIDs in step 5 of the "Determining How Genetics Change Drug Responses" section. Use the list for this section.
/-/https/www.sciencebuddies.org/cdn/Files/4227/10/BioMed_img003.jpg)
The SNP database allows users to search specific alleles using their rsID numbers at the top of the page.
Figure 3. The SNP database has information on alleles of genes. You can search for alleles using their rsID number, as shown circled in green.
- You should see a search result page that lists that allele by its rsID, as shown in Figure 4. Click on the rsID, as shown in Figure 4, circled in green.
/-/https/www.sciencebuddies.org/cdn/Files/4228/20/Biomed-img004.png)
Search results on the website ncbi.nlm.nih.gov/projects/SNP show multiple results when searching for a specific allele. 9 related results are returned when searching for the allele rs1045642, the first result is for the specific allele that is found in humans (homo sapiens). Each results has a clickable link to a detailed page as well as genetic information listed beneath it.
Figure 4. When you search for a gene allele on the SNP database using its rsID you will get a result like this. Click on the rsID, circled in green, to go to a page with information on the allele.
- You should see a page with information on that allele.
- Go to the NCBI Gene & SNP Tutorial and scroll down until you reach the section titled "I want to look up a gene involved in a genetic disease and find out how it is mutated in that disease. How can I do this?" In this section, scroll down until you reach step 4 and follow the instructions (start on step 4a).
- On the page for your allele, on the line immediately under where it says "GeneView," make sure that the name of your gene matches the gene name given there, as shown for the ABCB1 allele in Figure 5, circled in green.
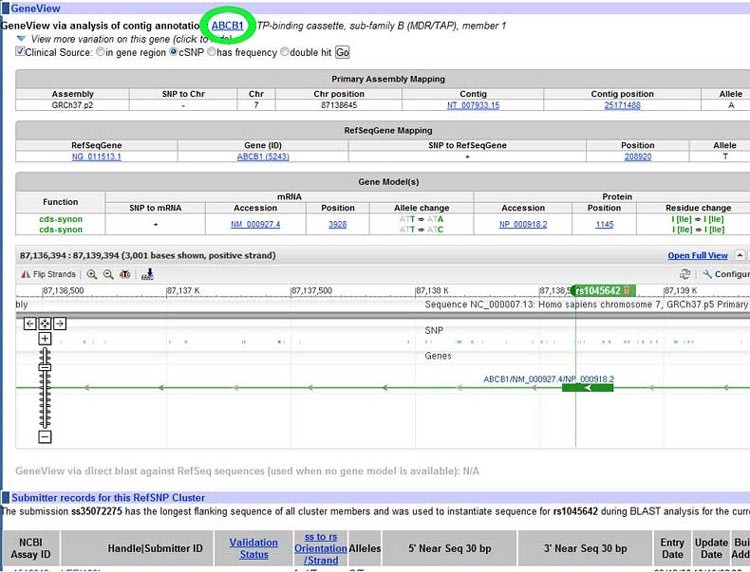
The GeneView page shows mapping and model information for gene ABCB1. The page includes: primary assembly mapping, gene mapping and gene models.
Figure 5. The SNP database page for a given gene allele has a large amount of information. Before diving into the data, confirm that the page is for your gene of interest, as shown in a search for an allele of the ABCB1 gene, circled in green.
- In Table 2, record whether the allele change is in an exon, an intron, or some other part of the gene.
- If in the section labeled "Gene Model(s)" under "Residue change" there are amino acids listed, such as in Figure 5, then the mutation is in an exon.
- If there is no section labeled "Gene Model(s)," look to see if there is instead a heading called "Function class." If there is, under "Function class" it should say that the allele mutations are in an intron.
- Alleles may be caused by DNA mutations in other parts of the gene. If there are no amino acids under "Residue change" but instead it says "NA" then look to the far left column and see what is listed under "Function." If it says "nearGene," then the mutation is near the gene, but not inside the coding region.
- For examples of alleles with mutations in introns or exons, search the SNP database for the rsID of alleles already listed in Table 2.
- If the allele mutation is in an exon do the following (otherwise skip to step 6):
- Record the corresponding "Allele change" for each allele in your lab notebook. Put this in the "Codon Sequence Change (DNA)" column of Table 2. This is the DNA nucleotide that has changed.
- If multiple rows of allele changes are listed, pick one at a time.
- Convert the DNA sequence to mRNA, by changing every T to a U, and record this in your lab notebook in Table 2, under the "Codon Sequence Change (mRNA)" column.
- For example, CCA would still be CCA, and GTG would be converted to GUG.
- To determine if and how the DNA change caused a change in the amino acid the gene makes, look at Figure 6.
- Record this in the "Amino Acid Sequence Change" column of Table 2.
- This entry should match the "Residue change" that you observed in step 5c.
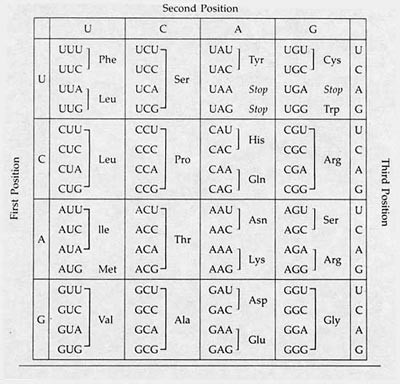
A DNA sequence is altered to change the nucleotide T to a U and a table is used to convert the altered DNA sequences into set of 3 mRNA nucleotides called codons which code for a specific amino acid.
Figure 6. A DNA sequence is converted into mRNA, and every three mRNA nucleotides (called "codons") code for a certain amino acid. This figure shows what mRNA codons code for what amino acids. A protein is made up of a sequence of several specific amino acids. Consequently, a gene's mutated DNA can ultimately change the function of the protein that is made (image courtesy of Schering-Plough). - If the normal amino acid is different from the one made by the allele change, what DNA mutations would not have caused a change in the amino acid that is made?
- If the amino acid that is made by the mutant allele did not change, what DNA mutations would have caused a change?
- Record the corresponding "Allele change" for each allele in your lab notebook. Put this in the "Codon Sequence Change (DNA)" column of Table 2. This is the DNA nucleotide that has changed.
- If the allele mutation is in an intron or a part other than an exon in the gene, do the following:
- For this allele, write "N/A" in Table 2 for the columns labeled "Codon Sequence Change (DNA)," "Codon Sequence Change (mRNA)," and "Amino Acid Sequence Change."
- To finish analyzing this allele mutation, skip to the section titled "The Importance of Non-Coding Regions".
/-/https/www.sciencebuddies.org/cdn/Files/4229/10/BioMed_img005.jpg)
/-/https/www.sciencebuddies.org/cdn/Files/4230/14/BioMed_img006.jpg)
How Amino Acid Changes Matter
If your allele mutation was in an exon, you now know which amino acids are mutated in the alleles that are associated with an unusual response to the drug, giving you a better idea of the drug's pharmacogenomics. But why does this mutation affect the normal function of the protein?
- For each allele with a mutation in an exon, look at the "Amino Acid Sequence Change" you entered in Table 2.
- If the normal amino acid is different from the one made by the allele change, look at Table 3 to determine how these amino acids are different from each other.
- If your allele mutation was in an exon but there was no amino acid change, such as with the ABCB1 allele listed in Table 2, for this allele skip to the section titled "The Importance of Non-Coding Regions".
- Record in your lab notebook in Table 2, under the column labeled "Effect," what the differences are between the normal and mutant amino acids.
- To see an example, look at the entry for the CYP2C19 allele in the column "Effect."
- How do you think these differences affect how the protein as a whole functions?
- What kind of amino acid mutations would be less likely to change the protein's normal function?
| Amino Acid Charge Property | Full Amino Acid Name | 3-Letter Name | 1-Letter Name |
|---|---|---|---|
| Nonpolar Amino Acids | Alanine | Ala | A |
| Glycine | Gly | G | |
| Isoleucine | Ile | I | |
| Leucine | Leu | L | |
| Methionine | Met | M | |
| Valine | Val | V | |
| Polar, Uncharged Amino Acids | Asparagine | Asn | N |
| Cysteine | Cys | C | |
| Glutamine | Gln | Q | |
| Proline | Pro | P | |
| Serine | Ser | S | |
| Threonine | Thr | T | |
| Aromatic Amino Acids | Phenylalanine | Phe | F |
| Tryptophan | Trp | W | |
| Tyrosine | Tyr | Y | |
| Positively Charged Amino Acids | Arginine | Arg | R |
| Histidine | His | H | |
| Lysine | Lys | K | |
| Negatively Charged Amino Acids | Aspartic Acid | Asp | D |
| Glutamic Acid | Glu | E |
- Go back to the "Pathways" tab for your drug of interest in PharmGKB (step 4 in the section titled "Determining How Genetics Change Drug Responses").
- If the function of this protein changes, how do you think this affects how the drug functions in the pathway?
- Is your hypothesis similar to what is known about how this allele mutation changes a patient's response to the drug?
- To learn about how you can investigate target-drug interactions in 3D space using modeling programs, read the Variations.
The Importance of Non-Coding DNA
Some mutations may be involved in how DNA is turned into mRNA. There are two main ways to know if your allele fits this category. The first is if your allele contains a mutation in an intron or another DNA area that is not an exon, areas termed "non-coding DNA" because they do not code for protein. Or the second is if your allele contains a mutation in an exon that does not change what amino acid is normally made. In both these cases of "non-coding DNA," the mutation may be in the middle of instructions for how the gene should be properly turned into mRNA, such as how the pre-mRNA should be cut apart and reassembled into mRNA. Additionally, DNA that is inside of one gene may actually be important for how a nearby gene is processed. If you are interested in tackling the puzzle of how an allele with this kind of mutation can affect drug response, read the Variations.
Ask an Expert
Global Goals
The United Nations Sustainable Development Goals (UNSDGs) are a blueprint to achieve a better and more sustainable future for all.
/-/https/www.sciencebuddies.org/cdn/Files/19746/5/E-WEB-Goal-03.png)
Variations
- Now that you can find how a gene mutation can change a patient's response to a drug and why pharmacogenomics are important for testing new drugs, repeat the procedure above for additional alleles or other drugs, such as carbamazepine, mercaptopurine, warfarin, or others listed in Table 1 above.
- If you investigated an allele with a mutation in non-coding DNA, try to find out how that mutation may affect how a patient with that allele responds to the drug.
- When looking at the SNP database page for your allele (as you did in the section titled "Identifying the Mutations" in step 5), look near the bottom of the "GeneView" section where there should be one or more horizontal green lines.
- This is a map showing the location of your allele SNP in the gene (both the SNP location and gene are in green) and where this gene is located relative to other nearby genes on the chromosome (the other genes are green as well). Move your mouse over the green lines to see the gene names. Zoom out by clicking the "-" button at the top. Click this a few times until you can see your entire gene, in green. Roughly where is the mutation located in the gene, on one end or in the middle?
- Click the zoom out button several times until you can see about 10 genes near yours, which are all in green. Are any of these genes involved in the pathway for your drug of interest?
- In this science project you focused on looking at alleles of genes that were shown in the "Pathways" tab for a given drug on PharmGKB (as discussed in the section titled "Determining How Genetics Change Drug Responses" on step 5). However, for some drugs there are alleles of genes listed in the "Clinical PGx" tab, but these genes are not in the "Pathways" tab. Think about how these gene alleles may affect the function of the drug and what role they may play in its pharmacogenomics.
- For some drugs you can investigate where the amino acid in the target protein is mutated relative to where the protein is bound by the drug, all in 3D space using chemistry modeling programs. Try the steps below with the drug Erlotinib and its target protein EGFR, which have the most data available. A mutation in the EGFR gene with the rsID of rs2227983 results in an amino acid change.
- First go to http://www.bindingdb.org.
- Search for your drug name in the "Full Search" box.
- Click on its chemical structure, shown under the heading "Link to Data."
- If there are multiple results, you may need to look at multiple ones before finding one with the necessary data.
- Here you can view the 3D structure of the drug rotating freely. Under the column titled "Trg + Lig Links," click on the "PDB" link.
- The column titled "Trg + Lig Links" gives links to structures of the target (the protein the drug binds) and the liggand (the drug) when the two are bound together.
- If there are multiple entries, scroll through them until you see a link to "PDB."
- On this page, scroll down and click on the title of the search result. This title will include the drug name along with the name of the target it is interacting with.
- On the right side of this page click on "SimpleViewer." Launch RCSB - Simple Viewer or save the file and open it. You will need a current version of Java to run this program.
- Here you will see a 3D model of the drug interacting with the target protein. You can rotate the image using left click and drag. You can zoom by holding shift while using left click and drag.
- Is the drug bound on the inside or on the surface of the target protein?
- Hover your mouse over different parts of the protein to see which amino acid that part of the protein is made of. This is displayed in the bottom left corner of the window.
- For example, "Reside: Ser 852 Chain: A Confirmation: Helix" means that you are hovering over a serine amino acid that is at position 852 in the protein. This amino acid is part of an alpha helix in the protein.
- For alleles with a mutation in an exon, the amino acid position of the mutation is listed on the allele SNP page in the "Gene Model(s)" section under "Protein," under "Position."
- Try locating the mutated amino acid in the model. Is it close to where the drug binds, or is it far away?
- Can you see which amino acids are interacting with the drug the most, and can you determine what kind of bonds are being formed based on your knowledge of the drug structure?
- You can repeat the above steps using other drugs to view interactions with their targets in 3D space. Some drugs with sufficient data to view these interactions (and to track the target proteins back to the signaling pathways seen in step 5b in the section titled "Determining How Genetics Change Drug Responses" above) include: Atorvastatin, Gefitinib, and Imatinib.
Careers
If you like this project, you might enjoy exploring these related careers:
/-/https/careerdiscovery.sciencebuddies.org/cdn/Files/1338/23/pexels-photo-3958380.jpg)
/-/https/careerdiscovery.sciencebuddies.org/cdn/Files/1171/18/pexels-photo-4033151.jpg)
/-/https/careerdiscovery.sciencebuddies.org/cdn/Files/956/18/unsplash-mVV0s8ZvEm4.jpg)
/-/https/careerdiscovery.sciencebuddies.org/cdn/Files/17070/11/pexels-photo-5716042.jpg)
/-/https/careerdiscovery.sciencebuddies.org/cdn/Files/19477/4/nurse-practioner-holding-hands-patient.jpg)

/-/https/img.youtube.com/vi/6nEH2XlcJt8/0.jpg)
/-/https/img.youtube.com/vi/GqxGn-7kQZY/0.jpg)
/-/https/img.youtube.com/vi/a0A-JbP9T0I/0.jpg)