Abstract
Our genes are made up of hundreds to millions of building blocks, called DNA nucleotides, and if just a single nucleotide of DNA becomes mutated it might cause a devastating genetic disease. But sometimes a mutation actually does no damage. What kinds of mutations have to occur to cause a genetic disease? In this science project, you will explore online genetic databases to identify how a mutation in a gene can result in a dysfunctional protein, and how other mutations may have no effect at all.Summary
Teisha Rowland, PhD, Science Buddies
Sandra Slutz, PhD, Science Buddies
Svenja Lohner, PhD, Science Buddies
/-/https/www.sciencebuddies.org/cdn/Files/12110/9/DNA-SNP-thumbnail.jpg)
Objective
Determine why some gene mutations cause genetic diseases, but others do not.
Introduction
/-/https/www.sciencebuddies.org/cdn/Files/12110/9/DNA-SNP-thumbnail.jpg)
The Human Genome Project has estimated that the human genome contains around 20,000 to 25,000 genes. Each of these genes is made up of hundreds to millions of DNA nucleotides. Sometimes only a single DNA mutation (change in the DNA sequence) can cause a person to have a devastating genetic disease, and researchers have been able to identify mutations responsible for causing thousands of different genetic diseases and conditions. But sometimes a DNA mutation may do no harm at all. It all has to do with what the DNA mutation is and where it is located.
Every gene in the human body consists of DNA (deoxyribonucleic acid). DNA is a genetic code that is made up of four different types of nucleotides: adenine (A), thymine (T), guanine (G), and cytosine (C). This DNA code is turned into RNA (ribonucleic acid) in our bodies in a process called transcription. In RNA, a nucleotide called uracil substitutes for every thymine. The RNA then goes through a process called translation to turn into amino acids. During translation, every three RNA nucleotides code for a single amino acid. This set of three nucleotides is called a "codon," and different codons may code for the same amino acid. In the end, a sequence of DNA has been turned into a sequence of amino acids joined together in a long chain, which is called a protein. Proteins are responsible for most of the functions of our cells.
Many things can happen during this process to prevent a gene from turning into protein or to have a non-functional protein created. In a gene, if a single DNA nucleotide is mutated, for example from an adenine (A) to a guanine (G), this may cause the wrong amino acid to be made. If the wrong amino acid is made and assembled into a long chain of amino acids, the resulting protein may not work. This is because different amino acids are different in many ways, such as size and in the electric charges they have. These different characteristics affect how they interact with each other as well as the other molecules that surround them (such as other amino acids and water). For example, positively and negatively charged molecules prefer to interact with each other and with water, which is called being hydrophilic, whereas nonpolar molecules do not like to interact with charged molecules or with water, which is called being hydrophobic. These seemingly small differences can have very large consequences.
For example, in cystic fibrosis there is a mutation in a gene, called the CFTR gene, that encodes for a channel that controls the flow of particles in cells. Specifically, this channel normally regulates whether small negatively charged particles, called chloride ions, can flow into, or flow out of, the cells. The movement of charged particles acts to balance the flow of water into, and out of, the cells. In people with cystic fibrosis, the mutated CFTR gene creates a channel that does not function, and consequently the flow of water in tissues is abnormal. In turn, the abnormal flow of water causes a build up of thick mucus on the lining of many internal organs and can have many other devastating effects on different parts of the body (see Figure 1).
/-/https/www.sciencebuddies.org/cdn/Files/4231/10/BioMed_img020.jpg)
A diagram shows an outline of the human body with different bodily systems labeled if they are affected by cystic fibrosis. 12 systems are labeled with associated medical conditions: General (2 conditions), Nose and sinuses (2 conditions), Liver (2 conditions), Gallbladder (3 conditions), Bone (3 conditions), Intestines (10 conditions), Lungs (12 conditions), Heart (2 conditions), Spleen (1 condition), Stomach (1 condition), Pancreas (4 conditions) and Reproductive (3 conditions).
Figure 1. Cystic fibrosis is caused by a mutation in the CFTR gene, which encodes for a chloride channel that is important for regulating water flow into, and out of, the cells. Because so many bodily functions rely on normal water flow, a disruption in water flow can cause a number of devastating effects, as shown in the "Manifestations of Cystic Fibrosis" image (Wikimedia Commons, 2011)
While DNA mutations clearly cause a number of genetic diseases, some DNA mutations may not be problematic. In this science project, you will investigate cystic fibrosis and the genetic mutations that cause it, using online genetic databases. This investigation will allow you to determine what type of mutations may alter the function of a protein and which ones may have little or no effect.
Terms and Concepts
- Genes
- DNA
- Mutation
- Genetic disease
- Nucleotides
- RNA
- Transcription
- Translation
- Amino acids
- Codon
- Hydrophilic
- Hydrophobic
- Allele
Questions
- How does a gene become a protein?
- In a given gene, what kind of DNA mutation would not change the protein that is made?
- What makes some amino acids hydrophobic and others hydrophilic?
- How common are mutations in the human genome? Is it very likely or very unlikely that your DNA carries any mutations?
Bibliography
To do this science project you will need to use these databases:
- Medline Plus. (n.d.). Genetics.. Retrieved October 25, 2021.
- NCBI. (n.d.). Gene. Retrieved August 17, 2011.
- NCBI. (n.d.). dbSNP Short Genetic Variations. Retrieved August 17, 2011.
These resources are a good place to start gathering information about genetics, genetic diseases, and gene testing:
- Medline Plus. (n.d.). Genetics.. Retrieved October 25, 2021.
- National Cancer Institute at the National Institutes of Health. (n.d.). What is genetic testing? Retrieved August 31, 2021.
- National Human Genome Research Institute (n.d.). The Human Genome Project. Retrieved August 31, 2021.
- Oak Ridge National Laboratory. (n.d.). Basics of the CTFR Protein. Retrieved August 31, 2021.
- Davies, J.C. et al. (2007). Cystic Fibrosis. British medical journal, Vol 335, No 7632, 1255-1259. Retrieved August 31, 2021.
- Russell, R. et al. (2003). Amino Acid Properties. Retrieved August 31, 2021.
- The University of Utah, Genetic Science Learning Center. (n.d.) Learn.Genetics™. Retrieved August 31, 2021.
Information about the non-pathogenic CFTR alleles in Table 2 was taken from these sources:
- Dequeker, E. et al. (2008, August 6). Best practice guidelines for molecular genetic diagnosis of cystic fibrosis and CFTR-related disorders-updated European recommendations. European Journal of Human Genetics, Vol 17, No 1, 51-65. Retrieved August 31, 2021.
- Bombieri, C. et al. (2000). A new approach for identifying non-pathogenic mutations. An analysis of the cystic fibrosis transmembrane regulator gene in normal individuals. Human Genetics, Vol 106, No 2, 172-178. Retrieved August 31, 2021.
Materials and Equipment
- Computer with an Internet connection
- Lab notebook
Experimental Procedure
Determining How a Disease Gene Is Mutated
This science project focuses on the genetic disease cystic fibrosis, but you can do it with any genetic disease you would like to choose. See the Variations section and Table 4 for information on doing this science project with genetic diseases other than cystic fibrosis.
The first step of this project is to find more information about cystic fibrosis. Go to the Medline Plus Genetics site, which is an online tool and resource for the general public to identify and learn about genetic mutations responsible for genetic diseases.
- On the Medline Plus Genetics website, click on "Genetic Conditions." In this section, you can find information on hundreds of genetic conditions listed alphabetically.
- Click on the letter "C" and scroll down until you see "cystic fibrosis" and click on it. On this page, you can find the following:
- A general description of the disease.
- Information about how common the disease is.
- Information about the causes of the disease. This includes information about the gene(s) that are related to the disease.
- Information about how the disease is inherited.
- Links to additional information related to cystic fibrosis.
- Read through the entry on the genetic disease, paying special attention to the genetic changes that cause the disease. What does the entry on cystic fibrosis tell you about its genetic causes? How are the chloride channels different in cystic fibrosis, and how does this affect the body as a whole?
- Record in your notebook the following information:
- The symptoms and problems of the genetic disease.
- The name of the gene (or genes) that is mutated.
The next step is to find out more about the CFTR gene.
- Go back to the Medline Plus Genetics main site and click on the "Genes" section. In the "Genes" section, you can look up specific genes and find a variety of information on them, including their effects on health and genetics and how they are grouped together.
- Click on the letter "C" and scroll down until you see "CFTR" and click on it. On this page, you can find the following:
- The official name of the gene.
- The normal function of the gene.
- The health conditions related to genetic changes of the gene.
- How the gene has been changed to cause the genetic disease.
- The chromosome location of the gene.
- Links to additional information relating to the gene, as well as other genetics resources.
- Read about the CFTR gene and how it is involved in cystic fibrosis. What chromosome is the CFTR gene located on? What amino acids in the CFTR gene are commonly mutated to cause cystic fibrosis?
From DNA to Amino Acids
Once you have gathered the information on cystic fibrosis and the CFTR gene, you can figure out if and how a simple mutation in the DNA ended up changing the amino acids that are made, as well as the function of the entire protein. You will use the National Center for Biotechnology Information (NCBI) Gene database to learn more about the gene sequence, gene alleles, and mutations of the CFTR gene. Before you continue, it might be helpful to familiarize yourself with the NCBI website by watching the NCBI tutorial below.
/-/https/i.ytimg.com/vi/QLcmEqBayr0/maxresdefault.jpg)
Table 3 has been partly filled in with information on non-pathogenic alleles of the CFTR gene. Alleles are alternative forms of a gene that occur through mutation of the DNA. Non-pathogenic alleles are alleles that have been shown to not cause cystic fibrosis. They are mutations that do not affect if a person gets the disease or not. This is the opposite of pathogenic alleles, which are alleles that are known to be harmful and actually cause the disease. In this part of the science project, you will be filling in the rest of Table 3 with additional information on these non-pathogenic alleles. You will also select ten pathogenic alleles and fill in their information in the remaining empty rows in Table 3.
- Copy Table 3 into your lab notebook. You will pick ten pathogenic alleles for cystic fibrosis and fill in Table 3 accordingly.
- Go to the NCBI Gene database website. At the top, enter the name of your gene of interest ("CFTR") and click "Search."
- The resulting page, shown in Figure 2, may have a long list of related results. The top results are usually the most relevant ones. You are looking for the first entry that both starts with CFTR and includes the species name for humans (Homo sapiens). In Figure 2, this is the first result; click on it to proceed to the gene page.
/-/https/www.sciencebuddies.org/cdn/Files/17787/11/fig2-gene-CFTR-search-results.png)
Screenshot of search results on the ncbi.nlm.nih.gov website. Searching for the gene CFTR shows a list of results that provide a gene name, gene ID, description, location, aliases and a mendelian inheritance in man value (MIM).
Figure 2. When you enter the gene name CFTR, you will get many results on the NCBI Gene database. The gene name is given on the left, followed by its description (unabbreviated name) in the second column. The species name is given in brackets at the end of the description entry. Additional gene information, including the chromosome location, is given in the columns farther to the right. Pick the top gene result, (circled in red) for this project.
- The gene page contains a large amount of information about the CFTR gene.
- Use the table of contents on the right side of the page to navigate to different information on the gene page.
Table 1 gives an overview of the different types of information provided.
Swipe left to see more
Table 1. On the right side of the NCBI Gene page for a given gene, there is a list of links in the "Table of contents." This table shows what information these links will provide.Link Name What Information It Provides Summary Summary of the gene name and its known functions. Genomic context A graphical representation of where the gene is located on the chromosome. Genomic regions, transcripts,
and productsA graphical representation of different areas of the gene, including where known mutations are located. Expression A graphical display of expression data for the gene in different tissue types. Bibliography Scientific articles related to this gene. Phenotypes Diseases and conditions related to mutations in this gene. Variation Collection of known variants of this gene. Pathways from BioSystems Metabolic pathways the gene is involved in. Interactions Proteins known to interact with the protein made by this gene. General gene info General information on the gene, including: - Other animals this gene belongs to (under "Homology")
- Pathways that this gene is involved in (under "Pathways from BioSystems")
- The different functions the protein made from this gene has (under "Gene Ontology")
General protein info Names of the protein made from this gene. NCBI Reference sequences (RefSeq) Links to where you can find the entire DNA sequence of this gene. Related sequences Sequences closely related to this gene. Additional links Links to more information on this gene and other genetic tools.
- Use the "Related information" section on the ride side of the page to navigate to additional NCBI pages with information on the gene and its role in human biology. Table 2 highlights some of the links that are particularly relevant to learning more about the gene's normal and disease functions.
Swipe left to see more
Table 2. On the right side of the NCBI Gene page for a given gene, there is a list of links in the "Related information" section. This table shows what resources some of these links will provide.Link Name What Information It Provides BioProjects Chromosome and sequencing studies that have involved the gene. BioSystems Bodily functions the gene may be involved in. Conserved Domains Functional domains, which are DNA regions that form distinct protein structures that affect the overall function of the protein. Functional domains are shared, or "conserved," among different members of the same gene family. Full text in PMC Scientific articles, with free access to full text, published on the gene. GEO Profiles How much protein is made from this gene in different tissues and in scientific studies, referred to as the gene's expression profile. HomoloGene A list of potential homologs of the gene (evolutionarily related genes in different animals) Nucleotide Links to where you can find the DNA sequence of the gene. OMIM Information about the gene on the OMIM database. The links here discuss the history and discovery of the gene, its function, how the disease manifests, and more. Protein Links to where you can find the amino acid sequence of the protein the gene codes for. PubMed Scientific articles published on the gene. Note: Some articles cannot be freely accessed. RefSeq Proteins Amino acid sequence of the protein the gene codes for and additional gene information. RefSeq RNAs mRNA and amino acid sequences that the gene (DNA) codes for. RefSeqGene The genomic DNA sequence of the gene (includes introns and exons) and other information about the gene. SNP Links to where you can find short genetic variations of the gene. SNP: GeneView A list of short genetic variations of the gene and the functional amino acid changes they cause. Variation Viewer A list of the short genetic variations of the gene with a lot of information about the variations, including what the DNA mutations are and which variations are pathogenic.
- Use the table of contents on the right side of the page to navigate to different information on the gene page.
Table 1 gives an overview of the different types of information provided.
Once you have gathered information on the CFTR gene, the next step is to find mutated versions of the gene that cause cystic fibrosis.
- On the page for the CFTR gene, scroll down through the "Related information" section on the right until you see the "Variation Viewer" link. Click on this link.
- A gene can have many different alleles, or alternative forms that occur through mutation of the DNA. Each row of data on this page, shown in Figure 3, lists a different allele for the gene you just searched for.
- On the left side of the page you can choose different options to filter the data. Click on "Pathogenic" (circled in blue in Figure 3) to sort the alleles according to this criterion. Here are the different clinical interpretations for alleles:
- "Likely pathogenic:" Alleles that are thought to be likely to cause disease, but are not proven.
- "Pathogenic:" Alleles that have been proven to cause disease.
- Alleles for which the "Clinical interpretation" column is blank. There is "no data" for these alleles. These still could be pathogenic.
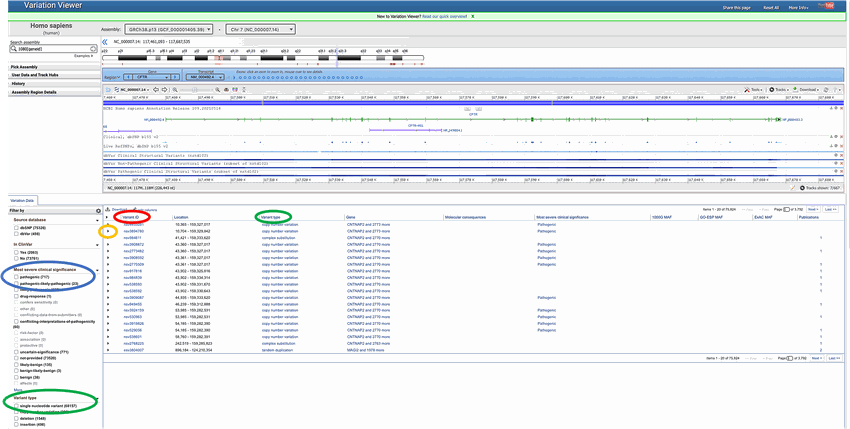
Screenshot of an allele chart on the ncbi.nlm.nih.gov website. The variation viewer window displays an allele chart for a given gene at the top of the page. At the bottom-left of the page filters can be applied to the chart to find specific alleles, such as ones that could be potentially pathogenic. Directly underneath the chart is a list of variants of alleles that display the variation type and location.
Figure 3. Clicking on "Variation Viewer" takes you to a table listing different alleles, or alternative forms that occur through mutation of the DNA, for your gene. Each row is a different allele of the gene. You can filter these alleles by their "Most severe clinical significance" (circled in blue), sort by "Variant type" (circled in green), or find more information about them by clicking on their "Variant ID" (circled in red).
- After filtering by "Most severe clinical significance," you should get a list of variants labeled only "Pathogenic" as their "Most severe clinical interpretation."
- You also want to filter the alleles according to their variant type. Check the box that says "Single nucleotide variant" (which means this variant type has a single nucleotide change), circled green in Figure 3.
- Once you have applied all your filter criteria (variant type, clinical significance, etc.), click on the arrow to the left of the variant ID (circled in yellow in Figure 3 and Figure 4) to open a drop-down window that provides more information on this specific gene variant. Here you will find more allele information, such as the "Transcript change," which lists what the DNA mutation is (circled in green in Figure 4) or the "Protein change" that result from the mutation (circled in red in Figure 4).
- On the left side of the page you can choose different options to filter the data. Click on "Pathogenic" (circled in blue in Figure 3) to sort the alleles according to this criterion. Here are the different clinical interpretations for alleles:
- From the resulting list, pick ten single nucleotide variant alleles that have "Pathogenic" as their "Most severe clinical interpretation." In your notebook, fill out Table 3 with the following information on the 10 pathogenic alleles you selected:
- The "Transcript change" which lists what the DNA mutation is. You get this information from the drop down table once you click on the arrow (circled yellow in Figure 4) to the left of the variant ID (circled blue in Figure 4). Put this information in the "Transcript mutation" column in Table 3.
- The "Variant ID". This is an identifier for this allele.
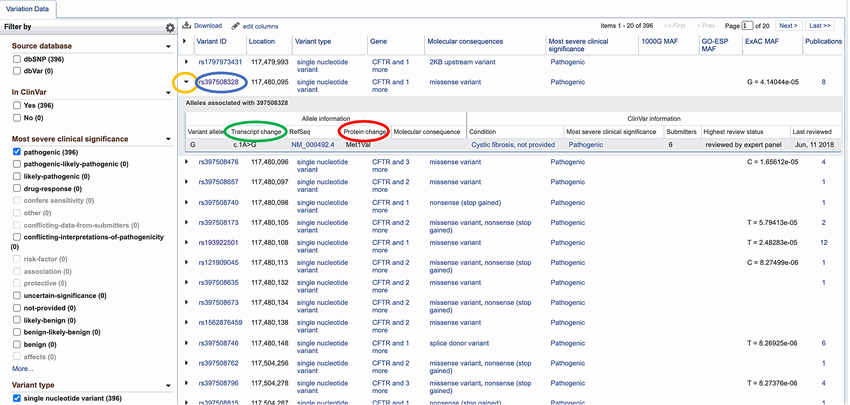
Screenshot of a list of variations in the variation viewer on the ncbi.nlm.nih.gov website. Variations in the variation viewer each have a small arrow to the left of each entry on the list. Clicking on the arrow of a specific allele variation shows additional information such as the transcript changes and protein changes in the variation.
Figure 4. Clicking on the small arrow (circled in yellow) to the left of the variant ID (circled in blue), pulls up more allele information, such as the "Transcript change" (circled in green) or "Protein change" (circled in red).
- For each selected allele, click on its "Variant ID" link (circled in blue in Figure 4), to go to a new page with information on that specific allele. This information is part of the SNP Database.
- For each allele page, go to the "Variant Details" tab and scroll down to the "Gene" section shown in Figure 5.
- Look where the changed "Amino acid [Codon]" is listed (circled yellow in Figure 5). There should be an amino acid mutation that matches the "Protein change" information that was listed with this allele on the previous page, which is circled in red in Figure 4.
- For example, the CFTR allele listed in Figure 4 had a protein mutation of "Met1Val" This means that the first amino acid in the protein has been changed from Methionine (abbreviated Met or M) to Valine (abbreviated Val or V). This matches the amino acid change listed as "M [Met] > V [Val]" in the "Amino acid [Codon]" column.
- Record the corresponding "Amino acid [Codon]" change for each of the ten alleles in your notebook. Put this in the "Codon Sequence Change (DNA)" column of Table 3. This is the DNA nucleotide that has changed.
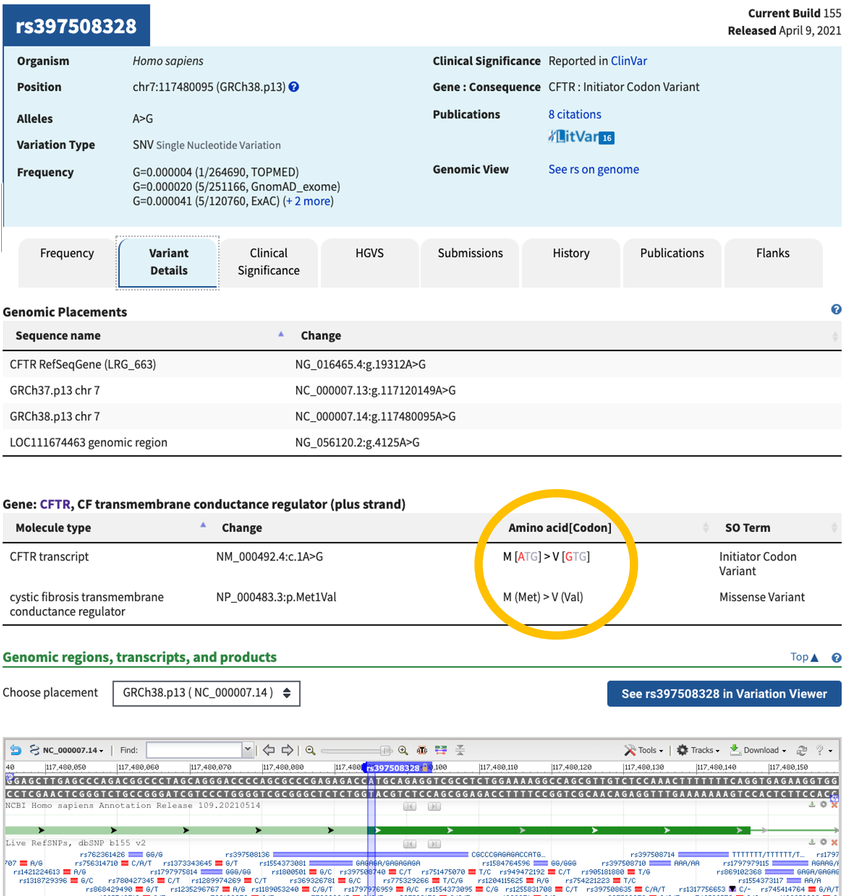
Screenshot of a of a specific variant page on the ncbi.nlm.nih.gov website. The page displays information on that specific allele and includes the 'Amino acid [Codon]' change of the allele (circled in yellow) as well as the location of the mutation within the gene sequence.
Figure 5. The variant ID page includes information such as the "Amino acid [Codon]" change of the allele (circled in yellow) and the location of the mutation within the gene sequence.
/-/https/www.sciencebuddies.org/cdn/Files/17788/11/fig3-variation-viewer.png)
/-/https/www.sciencebuddies.org/cdn/Files/17789/11/fig4-variant-mutations.png)
/-/https/www.sciencebuddies.org/cdn/Files/17790/14/fig5-snp-results.png)
| Transcript Mutation | rsID | Codon Sequence Change (DNA) | Codon Sequence Change (mRNA) | Amino Acid Sequence Change | Effect | Pathogenic or Non-Pathogenic |
| 1408G>A | rs213950 | GTG → ATG | GUG → AUG | V [Val] → M [Met] | Changes from a neutral, nonpolar amino acid to another neutral, nonpolar amino acid. | Non-Pathogenic |
| 1516A>G | rs1800091 | ATC → GTC | Non-Pathogenic | |||
| 4002A>G | N/A | CCA → CCG | Non-Pathogenic | |||
| 2694T>G | N/A | ACT → ACG | Non-Pathogenic | |||
| 4521G>A | N/A | CAG → CAA | Non-Pathogenic | |||
| Pathogenic | ||||||
| Pathogenic | ||||||
| Pathogenic | ||||||
| Pathogenic | ||||||
| Pathogenic | ||||||
| Pathogenic | ||||||
| Pathogenic | ||||||
| Pathogenic | ||||||
| Pathogenic | ||||||
| Pathogenic |
Table 3. This table contains information on five CFTR alleles that are known to not be pathogenic. Some of these alleles were taken from published scientific studies (see the Bibliography for the citations) and do not have assigned rsIDs (these are labeled "N/A"). For the first allele, all of the relevant information has been entered as an example. For the next four non-pathogenic alleles, fill in the information in the empty cells. Pick ten pathogenic alleles, and enter their information into the table as well.
- Convert the DNA sequence to mRNA, by changing every T to a U, and record this in your notebook in Table 3, under the "Codon Sequence Change (mRNA)" column.
- For example, GAG would still be GAG, and GTG would convert to GUG.
- Be sure to do this for the non-pathogenic alleles as well.
- To determine if and how the DNA change caused a change in the amino acid the gene makes, look at Figure 6.
- Record the amino acid sequence change in Table 3 under the "Amino Acid Sequence Change" column.
- Be sure to do this for the non-pathogenic alleles as well.
- This entry should match the "Amino acid [Codon]" change that you observed in step 8b.
- What DNA mutations would not have caused a change in the amino acid that is made?
- Do any of the non-pathogenic alleles have such a DNA mutation?
- On the gene SNP page, scroll down to "Genomic regions, trancripts, and products."
- You will see part of the sequence of the CFTR gene. The locations of many different gene mutations are shown underneath the sequence, each of which is linked to a different gene variant. You should be able to pick out where the mutated nucleotide of your selected gene variant is as the mutated base is highlighted in blue (Figure 5).
- What would have happened if the mutated nucleotide had instead been one of the nucleotides immediately adjacent to the actual mutated nucleotide?
- Record the amino acid sequence change in Table 3 under the "Amino Acid Sequence Change" column.
/-/https/www.sciencebuddies.org/cdn/Files/4232/14/BioMed_img006.jpg)
A DNA sequence is altered to change the nucleotide T to a U and a table is used to convert the altered DNA sequences into set of 3 mRNA nucleotides called codons which code for a specific amino acid.
Figure 6. A DNA sequence is converted into mRNA, and every three mRNA nucleotides (called "codons") code for a certain amino acid. This figure shows what mRNA codons code for what amino acids. A protein is made up of a sequence of several specific amino acids. Consequently, a gene's mutated DNA can ultimately change the function of the protein that results (image courtesy of Schering-Plough).
Testing How the Mutation Matters
You now know which amino acids are mutated in the genetic disease you're interested in, and how they became that way, but why is this mutation so damaging to the normal structure of the protein?
- For each allele, look at the "Amino Acid Sequence Change" you entered in Table 3.
- Look at Table 4 to determine how the normal amino acid and the mutant amino acid are different from each other.
- Record in your notebook in Table 3, under the column labeled "Effect," what the differences are between the normal and mutant amino acids.
- Be sure to do this for the non-pathogenic alleles as well.
- How do you think these differences affect how the protein as a whole functions?
- Why do you think the non-pathogenic alleles do not disrupt the protein's function?
| Electric Charge | Full Amino Acid Name | 3-Letter Name | 1-Letter Name |
| Nonpolar Amino Acids | Alanine | Ala | A |
|---|---|---|---|
| Glycine | Gly | G | |
| Isoleucine | Ile | I | |
| Leucine | Leu | L | |
| Methionine | Met | M | |
| Valine | Val | V | |
| Polar Uncharged Amino Acids | Asparagine | Asn | N |
| Cysteine | Cys | C | |
| Glutamine | Gln | Q | |
| Proline | Pro | P | |
| Serine | Ser | S | |
| Threonine | Thr | T | |
| Aromatic Amino Acids | Phenylalanine | Phe | F |
| Tryptophan | Trp | W | |
| Tyrosine | Tyr | Y | |
| Positively Charged Amino Acids | Arginine | Arg | R |
| Histidine | His | H | |
| Lysine | Lys | K | |
| Negatively Charged Amino Acids | Aspartic Acid | Asp | D |
| Glutamic Acid | Glu | E |
Table 4. Amino acids vary in whether they have an electric charge or have no charge. If they do have a charge, it can be positive or negative. They also vary in size. All of these factors affect how the amino acids interact with other amino acids in the same protein, and with other molecules, such as water, that are surrounding them. For more information, see this Amino acid properties webpage.
Ask an Expert
Global Goals
The United Nations Sustainable Development Goals (UNSDGs) are a blueprint to achieve a better and more sustainable future for all.
/-/https/www.sciencebuddies.org/cdn/Files/19746/5/E-WEB-Goal-03.png)
Variations
- Now that you know how to find how a gene mutation can cause a specific genetic disease, repeat the Experimental Procedure for other genetic diseases, such as sickle cell disease, hemochromatosis, or others listed in Table 3. Different amounts of information may be available for different diseases, and you may need to adjust the Experimental Procedure for some of these diseases. When investigating genetic diseases other than cystic fibrosis, you do not need to include non-pathogenic alleles.
| Genetic Diseases |
| Cystic fibrosis |
| Sickle cell disease |
| Hemochromatosis |
| Hemophilia |
| Factor V Leiden thrombophilia |
| Pompe disease |
| Neurofibromatosis type 1 |
| Lynch syndrome |
| Parkinson's disease |
| Crohn disease |
| Amyotrophic lateral sclerosis (Lou Gehrig's Disease) |
| Tourette syndrome |
| Bloom syndrome |
| Canavan disease |
| Gaucher disease |
| Niemann-Pick disease |
| Tay-Sachs disease |
| X-linked dystonia-parkinsonism |
Table 3. These well-studied genetic diseases and conditions have large amounts of data available on their genetic causes.
- If you repeat this project with a genetic disease other than cystic fibrosis, try doing a literature search for non-pathogenic alleles of the gene responsible for the disease. Incorporate the non-pathogenic alleles in to your project, and explain why they do not appear to be pathogenic while other mutations are. For help searching the literature read the guide to Resources for Finding and Accessing Scientific Literature. You may also find you need some help from someone experienced with genetics or bioinformatics to understand How to Read a Scientific Paper.
- While some gene mutations cause visible genetic diseases, other gene mutations do not significantly change the function of the protein.
- Looking at Figure 2 showing the amino acids that the different mRNA codons code for, what would be a less damaging DNA mutation?
- Looking at Table 2 and the link in its caption, what kind of amino acid mutations would be less likely to change a protein's normal function?
Careers
If you like this project, you might enjoy exploring these related careers:
/-/https/careerdiscovery.sciencebuddies.org/cdn/Files/1338/23/pexels-photo-3958380.jpg)
/-/https/careerdiscovery.sciencebuddies.org/cdn/Files/1628/18/iStock-1203995945.jpg)
/-/https/careerdiscovery.sciencebuddies.org/cdn/Files/1171/18/pexels-photo-4033151.jpg)
/-/https/careerdiscovery.sciencebuddies.org/cdn/Files/956/18/unsplash-mVV0s8ZvEm4.jpg)

/-/https/img.youtube.com/vi/OgRzJmu03VY/0.jpg)
/-/https/img.youtube.com/vi/bOyksqTQBgc/0.jpg)
/-/https/img.youtube.com/vi/lyvWd-TqqLI/0.jpg)