Abstract
Find out the real explanation for why your parents are so weird! Here is a science project that lets you explore the internet to find out why your "DNA blueprint" is so important to health and disease. In this science project, you will use methods that bioinformatics and biotech scientists perform on a daily basis to decipher the human genome in their efforts to diagnose and treat genetic diseases.Summary
Science Buddies would like to thank the following volunteers from Schering-Plough who contributed towards writing this project:
- Beth Basham Ph.D.
- Melissa Bilardello, B.S.
- Sarah Bodary, Ph.D.
- Jamie Furneisen. M.S.
- Jennifer Louten, Ph.D.
- Sheela Mohan-Peterson, J.D.
- Venkataraman Sriram, Ph.D.
Edited by Sara Agee, PhD, Teisha Rowland, PhD, Science Buddies, and Svenja Lohner, PhD, Science Buddies
Objective
Use publicly available web-based bioinformatics resources to search for a disease of interest and SNPs, single-nucleotide polymorphisms, associated with that disease.
Introduction
Biomedical Informatics is a broad discipline that encompasses bioinformatics and computational biology. Online bioinformatics resources, such as the database Online Mendelian Inheritance in Man, or OMIM, allow bioscience researchers to search up-to-date information on human genes, genetic traits and disorders. This project will take you through the step-by-step process of researching a specific disease of interest and how a single base change in one's DNA could be associated with that disease. This project should take approximately one week to complete.
Scientists are on a constant quest to improve and lengthen the quality of human life. DNA, the blueprint of life, has hidden clues for this quest. Identifying these clues is analogous to the cliché often heard "finding a needle in a haystack." The "haystack" for this project is the public bioinformatics databases, such as OMIM, containing a multitude of genetic information and the "needle" is the SNP, (pronounced snip), single-nucleotide polymorphism.
A Single Nucleotide Polymorphism, or SNP, is a small genetic change, or variation, that can occur within a person's DNA sequence. SNPs represent the most frequent type of DNA variation found in the human population. These variations can be used to study and track inheritance in families. Despite the fact that more than 99% of human DNA sequences are the same across the population, small variations in DNA sequence, such as SNPs, can have a major impact on how humans respond to disease, environmental factors, and medicines. Interestingly, SNPs are evolutionarily stable. This means they don't change much from generation to generation. That being said SNPs are of great interest and value for biomedical research. Developmental pharmaceutical products or medical diagnostics are being influenced by SNP data.
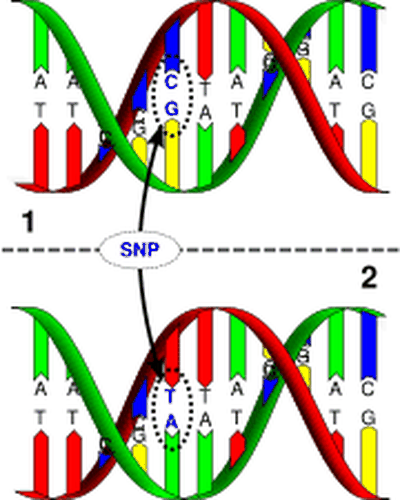
The cartoon depiction of a SNP in Figure 1, below, shows how DNA strand 1 differs from DNA strand 2 at a single base-pair location (a C/T polymorphism).
Drawing of two strands of DNA appear identical except for a single base pair that has been changed due to single nucleotide polymorphism. The top DNA strand contains a C and G base pair that is altered to an A and T base pair in the bottom DNA strand.
Figure 1. Here you can see a single nucleotide polymorphism, or SNP, that results in a small genetic change between sequence 1 and 2 (Wikipedia contributors, n.d.).
DNA, or deoxyribonucleic acid, supplies a set of instructions for each living organism. Every cell in each organism contains an entire copy of DNA. Genes are sets of nucleotide sequences encoded and stored in DNA. Each gene encodes for a certain protein. DNA is transcribed into mRNA, messenger ribonucleic acid, and then translated into protein. Proteins are defined by amino acid sequences. A single amino acid is encoded by three nucleotides called a codon. There are 64 possible codons and only 20 amino acids, as shown in Figure 2, below. Since there are only 20 amino acids, multiple codons encode for the same amino acid. This is known as degeneracy of the genetic code. Because of this degeneracy in the genetic code some SNPs do not result in changes in the protein sequence. This is called a synonymous change. If a SNP results in a change in the protein sequence this is termed a non-synonymous change. Finding single nucleotide changes in the human genome may be like "finding a needle in a haystack," however, bioinformatics resources make it possible to do just that.
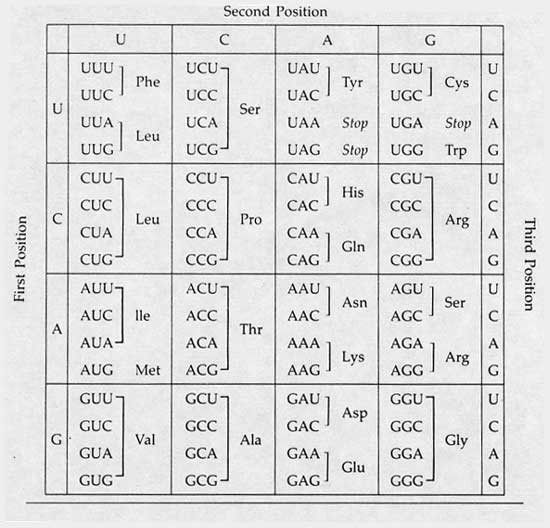
The genome codon table contains four rows and four columns (each labeled with the four nucleotides found in RNA). Each cell in the table contains four different combinations of three possible nucleotides and the resulting amino acid that would be produced.
Figure 2. This codon table shows how the genetic code is converted into a sequence of amino acids that make up a protein (image courtesy of Schering-Plough).
Variations in the DNA sequences of humans can affect how humans develop diseases and respond to medicines. Computational Biology, the actual process of analyzing and interpreting data, combined with Bioinformatics is used to for the technology called database-mining. With the completion of The Human Genome Project in 2003, vast amounts of genomic data have been made available for database-mining, the process of generating hypotheses regarding function or structure of a gene or protein of interest by identifying similar or dissimilar sequences in DNA. The International HapMap Project is designed to provide information to researchers with the HapMap, a catalog of common genetic variants that occur in human beings as well as a description of the variants and where they are located in our DNA. This catalog provided information that researchers need to link genetic variants to the risk for specific illnesses.
How do scientists utilize computers for mining of biological data to study genetics and disease association? In this science project, you will utilize the World Wide Web to access free bioinformatics resources to search for a disease of interest, identify SNP(s) associated with that disease, and make a hypothesis regarding the effect of the SNP(s). These public databases provide a vault of information that can be searched in many ways. We have provided one example; however, you may use your own method. With the availability of millions of SNPs, scientists now believe that exciting advances in medicine are in our near future. It is now your turn to mine databases for SNPs and make a hypothesis on the outcome on the human phenotype based on your research.
Terms and Concepts
To do this type of experiment you should know what the following terms mean. Have an adult help you search the internet, or take you to your local library to find out more!
- Allele - Alleles are different forms of the same gene. Allelic variation in a gene arises through mutation of the DNA sequence defining the gene and may or may not be associated with trait variation (e.g., height, eye color).
- Amino acid - The molecules that make up a protein. Each codon encodes for a specific amino acid.
- Bioinformatics - The collection, classification, storage, and analysis of large volumes of biological information (e.g., genomic, metabolomic, proteomic) using computers.
- Codon - Three bases in a DNA or RNA sequence which specify a single amino acid.
- DNA (Deoxyribonucleic Acid) - DNA is the chemical that forms a basic molecular code for how a living being should operate. DNA is the biological heredity material passed down from parent to child. Four bases called adenine (A), guanine (G), cytosine (C), and thymine (T) constitute DNA. It is present in the nucleus of almost all cells in an organism.
- Exons - Exons are sequences of DNA that code information for protein synthesis that are transcribed to messenger RNA, which in turn are translated into at least a portion of a protein.
- Gene - DNA sequences that contain a code that can be translated into a particular protein. For example, CFTR gene has the information that is necessary for a cell to make the CFTR protein.
- Genome - The DNA sequence of the entire organism's chromosomes. e.g., Human Genome
- Genomics - The study of the entire human genome. Genomics explores not only the actions of single genes, but also the interactions of multiple genes with each other and with the environment.
- Genotype - People inherit one allele for a gene from each parent such that they have two copies of each gene. The pair of alleles defines a person's genotype. For a gene that has two alleles in the population (e.g., an A allele and a G allele), there are three possible genotypes—AA, AG, and GG.
- HapMap - A partnership of scientists and funding agencies from Canada, China, Japan, Nigeria, the United Kingdom, and the United States to develop a public resource that will help researchers find genes associated with human disease and response to pharmaceuticals. HapMap's goal is to ultimately develop a haplotype map of the human genome and identify haplotype blocks.
- Homozygous - A genotype in which the two copies of the gene that determine a particular trait are the same.
- Heterozygous - Possessing two different forms of a particular gene, one inherited from each parent.
- Introns - Introns are segments of a genes situated between exons that are removed before translation of messenger RNA and do not function in coding for proteins or protein fragments.
- Junk DNA/Non-Coding Region - A region of the genome where the DNA has no known function (i.e., it does not code for a protein, regulatory sequence, or other functional elements). These regions usually consist of repeating DNA sequences. The majority of the human genome has no known function; only 2 percent to 5 percent of the DNA sequence codes for genes.
- Locus - The position of a gene on a chromosome. This term is a classical genetic concept used to understand gene order, gene distance, and gene function before gene and genomic DNA sequences were known.
- mRNA - Messenger RNA, or a single-stranded molecule of ribonucleic acid that is transcribed from the DNA and then translated into protein.
- Mutation - A mutation is a change in a DNA sequence. If the mutation occurs during the development of an egg or a sperm (i.e., gametes), then it becomes a heritable mutation. If the mutation occurs in any other body cell (i.e., part of the soma), then it is called a somatic mutation and it is not heritable. Somatic mutations are a cause of cancer. Mutations can be of many different types-substitutions, deletions, or insertions. Mutations in the DNA can be synonomous, e.g., not having any effect on the translated protein, or non-synonomous, causing amino acid changes in the translated protein.
- Non-synonymous change - If a SNP results in a change in the protein sequence.
- RNA (Ribonucleic Acid) - A chemical found in the nucleus and cytoplasm of cells; it transcribes the protein-coding instructions of DNA into a code that the protein-building ribosomes of a cell can understand. The chemical structure of RNA is similar to DNA-RNA also contains adenine (A), guanine (G), and cytosine (C), but instead of thymine (T), RNA contains uracil (U).
- SNPs (Single Nucleotide Polymorphisms) - Currently, there is estimated to be about 6 million positions in the human genome where a mutation occurred at a single nucleotide (A, T, C, or G) and both its alleles are now greater than 1 percent prevalent in the population. These SNPs are important for studies of genetic or genomic associations with disease because the alleles are common in the population.
- Synonymous change - If a SNP does not result in a change in the protein sequence. It is also known as a silent change.
Questions
This science project is based on research that provides often inconclusive but strongly correlative evidence that associates SNPs to risk of disease. The notion is that, with the availability of information about the complete human genome, we would be able to predict the risk of an individual contracting a disease or identify individuals with specific qualitative traits ('smart' genes, 'criminal' genes, 'intuition' genes etc.). One outcome of such advance would be personalized medicine where it is possible to treat each individual with a custom-made drug or even perform preventive therapy. However, on the flip side, ethical concerns need to be addressed with respect to individual human rights (The Minority Report movie debate).
Here are some questions that you will be thinking about while doing this science project:
- What is FASTA format?
- If two genes are homologous, are they similar?
- What are different types of mutations and how do they affect protein function?
- What is the probability of a single base mutation affecting protein function?
Bibliography
Here are some useful resources on SNPs and genetics that may help you complete this project:
- University of Utah, Health Sciences. (n.d.). Making SNPs Make Sense. Learn.Genetics. Genetic Science Learning Center. Retrieved October 8, 2014.
- Oak Ridge National Laboratory (ORNL). (February 2011). The Gene Gateway Workbook. U.S. Department of Energy Office of Biological and Environmental Research. Retrieved October 8, 2014.
- Moult, Y., Melamud, Z. (2005). SNPs3D. University of Maryland. Retrieved October 8, 2014.
Here are some useful textbooks with background information for you to review:
- Wood, E.J., Smith, C.A., Pickering, W.R. (eds), 1997. Life Chemistry and Molecular Biology, Portland, OR: Portland Press.
- Drlica, K., 1996. Understanding DNA and Gene Cloning: A Guide for the Curious, 3rd Ed., New York, NY: John Wiley & Sons.
Materials and Equipment
- Computer with Internet access
- Printer
- Lab notebook
Experimental Procedure
Searching for your disease
The OMIM database in NCBI is a catalog of human genes and genetic disorders authored and edited by Dr. Victor A. McKusick and his colleagues at Johns Hopkins and elsewhere, and developed for the World Wide Web by NCBI, the National Center for Biotechnology Information. The database contains textual information and references. It also contains copious links to MEDLINE and sequence records in the Entrez system, and links to additional related resources at NCBI and elsewhere.
- Search for the disease of your choice in the OMIM database, shown in Figure 3, below.
- For the purpose of simplifying directions, cystic fibrosis will be used as an example.
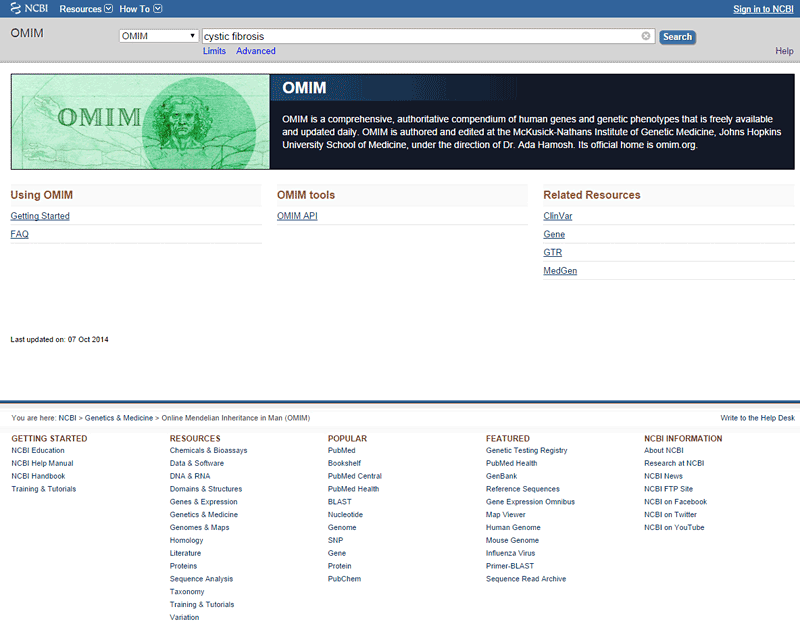 Image Credit: National Library of Medicine (NLM) / Public Domain
Image Credit: National Library of Medicine (NLM) / Public DomainScreenshot of the homepage of the ncbi.nlm.nih.gov/omim website. A search bar appears at the top and quick links to resources and gene tools are located at the bottom of the page.
Figure 3. The OMIM database has information on human genes and genetic disorders.
- Listed will be clinical results associated with your disease, as shown in Figure 4, below. These results will include genes as well as descriptions of related medical conditions. Click on the different results to see what they are. Find a result that is a gene and continue on to step 3.
- Tip: Gene entries are marked with an asterisk (*) in the list. Results that are genes will list a "HGNC Approved Gene Symbol" near the top of the webpage, as shown in Figure 5, below.
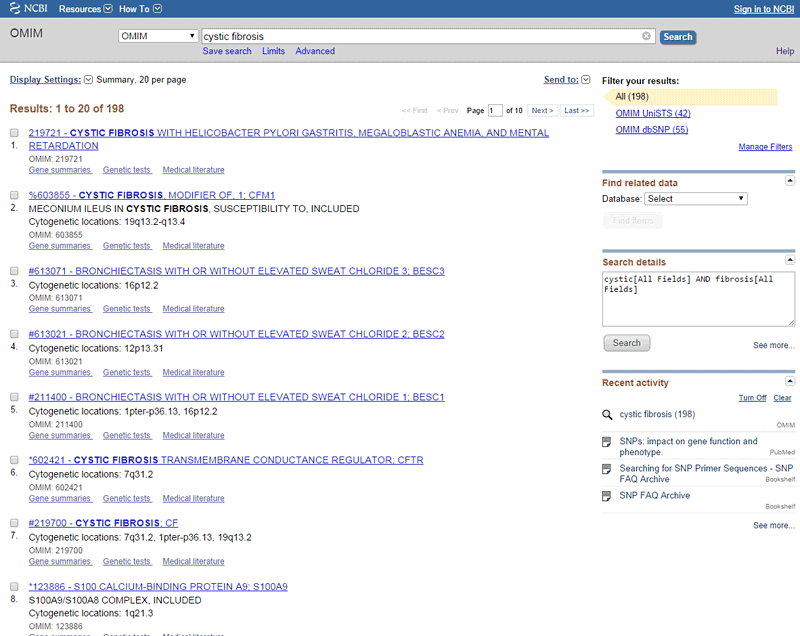 Image Credit: National Library of Medicine (NLM) / Public Domain
Image Credit: National Library of Medicine (NLM) / Public DomainScreenshot of a genetic disease search result for cystic fibrosis on the website ncbi.nlm.nih.gov/omim. A list of genes as well as related medical conditions appear in the results list.
Figure 4. When you search for a disease in the OMIM database, you will get many clinical results associated with the disease.
- The gene webpage will have lots of information on the disease-related gene, as shown in Figure 5, below. In your lab notebook, write down the "HGNC Approved Gene Symbol" for your gene.
- For example, for the cystic fibrosis gene shown in Figure 5, below, this would be CFTR.
 Image Credit: National Library of Medicine (NLM) / Public Domain
Image Credit: National Library of Medicine (NLM) / Public DomainScreenshot of the gene information page for cystic fibrosis on the website ncbi.nlm.nih.gov/omim. The specific gene appears at the top of the page with an abbreviation and full name written out. Near the top of the results page, under the gene heading, there is a smaller heading that states CFTR is a HGNC approved gene symbol. This symbol is specific to the cystic fibrosis gene.
Figure 5. Clicking on a gene results will bring you to a webpage with lots of information on that specific gene.
- On the right side of the gene webpage, under "External Links," click on the "Gene Info" heading, highlighted in orange in Figure 6, below. Then click on "NCBI Gene" from the dropdown menu. This will take you to the NCBI Gene database, which has additional information on the gene, as shown in Figure 7, below.
 Image Credit: National Library of Medicine (NLM) / Public Domain
Image Credit: National Library of Medicine (NLM) / Public DomainScreenshot of the gene information page for cystic fibrosis on the website ncbi.nlm.nih.gov/omim. The specific gene appears at the top of the page with an abbreviation and full name written out. General information about the gene is displayed in the middle of the page (including gene-phenotype relationships). A sidebar with additional links and resources can be found on the right side of the page. A menu option labeled 'Gene Info' can be found in the sidebar and contains a link labeled 'NCBI Gene'.
Figure 6. Clicking on "Gene Info," highlighted in orange here, will show you other databases with additional information on the gene. Clicking on "NCBI Gene" in this dropdown menu will take you to the NCBI Gene database.
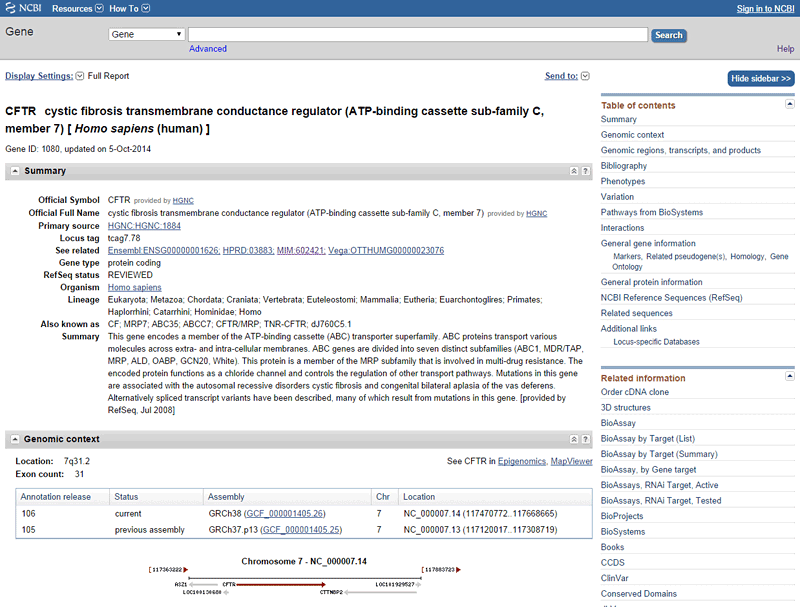 Image Credit: National Library of Medicine (NLM) / Public Domain
Image Credit: National Library of Medicine (NLM) / Public DomainScreenshot of the gene page for CFTR on the website ncbi.nlm.nih.gov/omim shows general information about the gene in a summary section located in the center of the page. A side bar on the right side of the page contains a table of contents and links to related information.
Figure 7. The NCBI database, shown here, will have additional information on the gene you found using the OMIM database.
- On the right side of the gene webpage, under "Related information," scroll down until you find "Variation Viewer" (as shown in Figure 8, below) and click on it. This will bring you to a webpage that lists all of the variants associated with the gene you chose above, as shown in Figure 9, below.
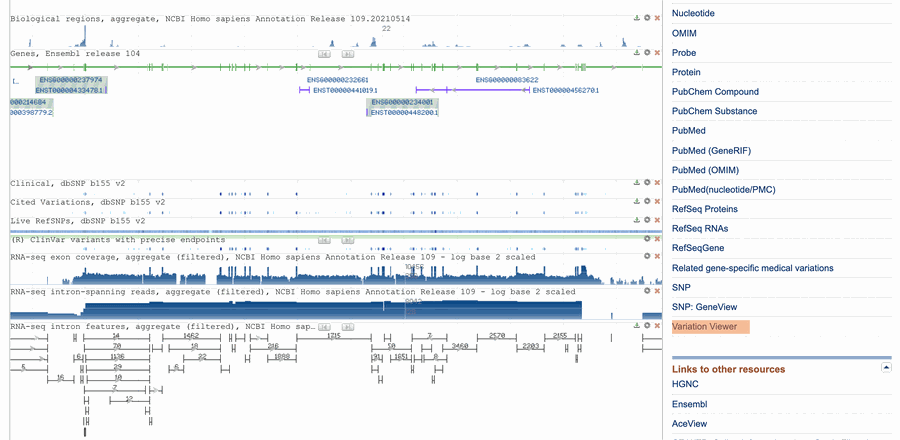 Image Credit: National Library of Medicine (NLM) / Public Domain
Image Credit: National Library of Medicine (NLM) / Public DomainScreenshot of the gene information page for CFTR on the website ncbi.nlm.nih.gov/omim shows more information about the CFTR gene. A link labeled 'Variation Viewer' can be found in the sidebar on the right of the page under the heading 'Related Information'.
Figure 8. Clicking on "Variation Viewer," highlighted in orange here, will take you to a webpage on the variants associated with the gene you chose.
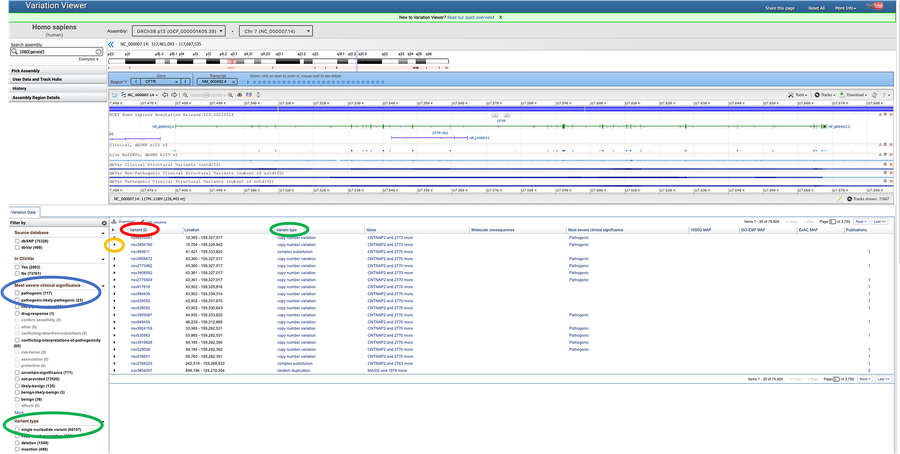 Image Credit: National Library of Medicine (NLM) / Purchased from istock
Image Credit: National Library of Medicine (NLM) / Purchased from istockScreenshot of an allele chart on the ncbi.nlm.nih.gov website. The variation viewer window displays an allele chart for a given gene at the top of the page. At the bottom-left of the page filters can be applied to the chart to find specific alleles, such as ones that could be potentially pathogenic. Directly underneath the chart is a list of variants of alleles that display the variation type and location.
Figure 9. Clicking on "Variation Viewer" takes you to a table listing different alleles, or alternative forms that occur through mutation of the DNA, for your gene. Each row is a different allele of the gene. You can filter these alleles by their "Most severe clinical significance" (circled in blue), sort by "Variant type" (circled in green), or find more information about them by clicking on their "Variant ID" (circled in red).
- Each row of data in the results table on this page, shown on the lower half of Figure 9, lists a different variant for the gene you just searched for. To navigate the large table of gene variants, here is a guide for the relevant columns in variant table:
- Variant ID: Unique identifier for the gene variant.
- Location: Genomic location of the variant.
- Variant type: The type of variant, e.g. single nucleotide variant.
- Molecular consequence: Consequences of the variation that can be computed from genes and other features annotated on the genome, e.g. nonsense, missense.
- Publication: Number of publications associated with the variant. Click on the linked value to view the publications in PubMed.
- On the left side of the page you can choose different options to filter the data. As you are interested in a genetic disease, click on "Pathogenic" (circled in blue in Figure 9) to sort the variants according to this criterion.
- You also want to filter the variants according to their variant type. Check the box that says "Single nucleotide variant" (which means this variant type has a single nucleotide change), circled green in Figure 9.
- Once you have applied all your filter criteria (variant type, clinical significance, etc.), click on the arrow to the left of the variant ID (circled in yellow in Figure 9) to open a drop-down window that provides more information on this specific gene variant. Here you will find more allele information, such as the "Transcript change," which lists what the DNA mutation is or the "Protein change" that result from the mutation.
- Find a SNP variant that has its "Molecular consequence" listed as "missense." Click on the "Variant ID" given for that SNP, as shown in the colum circled in red in Figure 9, above.
- This will take you to a webpage with information on the SNP variant, such as the sequence it occurs in, the location of the mutation, and other resources, as shown in Figure 10, below. Scroll down and review each tab to view and investigate all of the available information.
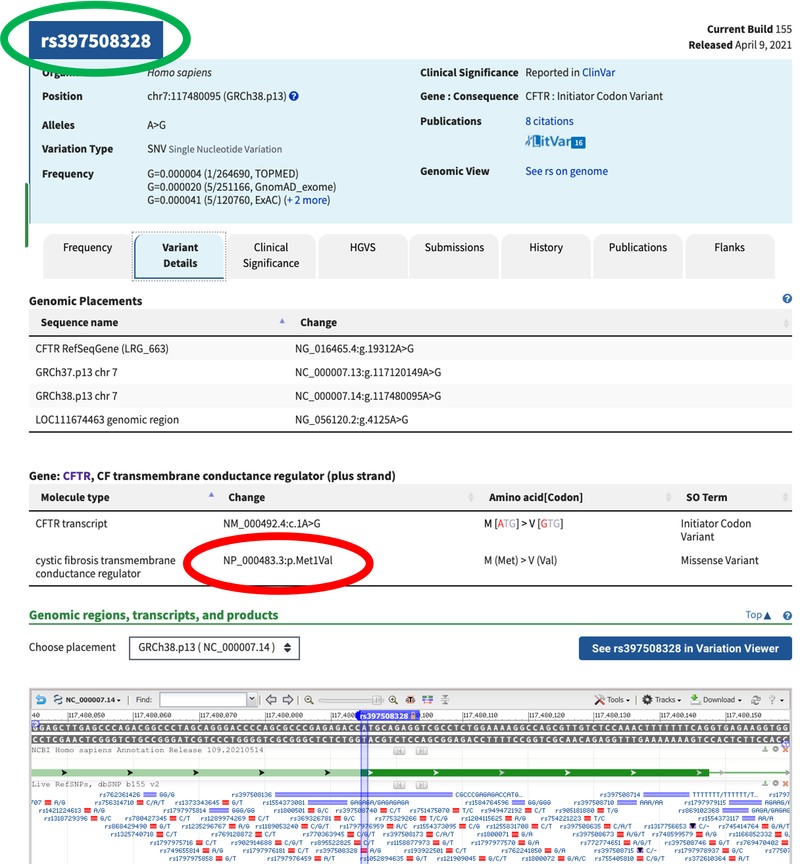 Image Credit: National Library of Medicine (NLM) / Purchased from istock
Image Credit: National Library of Medicine (NLM) / Purchased from istockScreenshot of an SNP cluster report page on the website ncbi.nlm.nih.gov/omim. A cluster ID is shown at the top of the page along with tables of information about the SNP below.
Figure 10. Clicking on a SNP Variant ID will take you to a webpage with a lot of information on the SNP. Explore the webpage to find out more about the SNP.
- In your lab notebook, write down the SNP rsID. This should be at the top of the webpage, as shown circled in green in Figure 10, above.
- For example, in Figure 10, above, the rsID is rs397508328.
- Click on the "Variant Details" tab to review the information provided there. In your lab notebook, write down the name that appears in the "Change" column of the "Gene" section that starts with "NP_000483," as shown circled in red in Figure 10, above.
- The right part of this name should include the amino acid change and the location of the change, for example, "Met1Val."
- To see if your SNP has an impact on protein structure and function, go to the SNPs3D website and search for the gene associated with your disease of interest, as shown in Figure 11, below.
 Image Credit: SNPs3D / Public Domain
Image Credit: SNPs3D / Public DomainScreenshot of the homepage of the website snps3d.org includes three search boxes allowing users to search the SNP database by gene, SNP ID, or disease.
Figure 11. The SNPs3D website has information on the impact of a SNP on protein structure and function, as well as other SNP-related information.
- You should see a gene webpage similar to Figure 12, below.
 Image Credit: SNPs3D / Public Domain
Image Credit: SNPs3D / Public DomainScreenshot of the results page on the website snps3d.org shows a rendered model of the CFTR gene on the left side of the page. The right side of the page contains information about the gene and SNP.
Figure 12. This is the SNPs3D webpage for a gene (CFTR, associated with cystic fibrosis).
- On the gene webpage, go to the "SNP information" section and search for your SNP of interest.
- You can find your SNP of interest by entering the amino acid change of your SNP into the search box (circled red in Figure 12.) For example, write "Met1Val," "Leu6Arg," or another amino acid change.
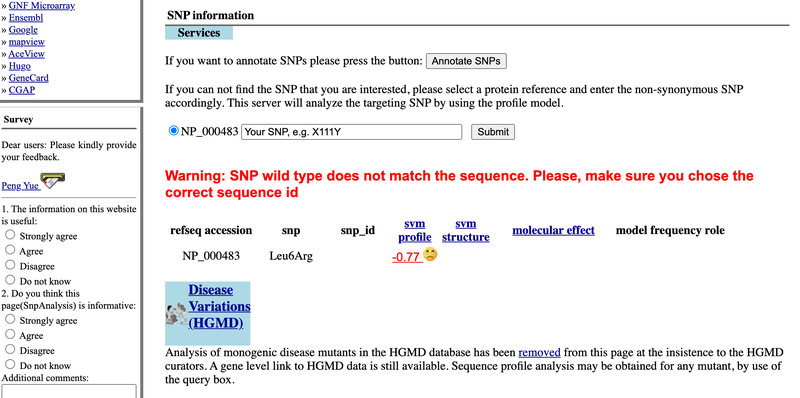 Image Credit: SNPs3D / Public Domain
Image Credit: SNPs3D / Public DomainScreenshot of the SNP results page on the website snps3d.org returns a list of related SNPs each with a unique ID, location and svm profile. A small penguin shaped icon will appear on the list of SNPs if that particular SNP has an associated model that can be viewed.
Figure 13. On the webpage for a gene on SNPs3D, you can search for specific SNPs. Each SNP will have numerical values that show how likely the SNP is to damage the protein. Negative red numbers indicate a likely damaging SNP, whereas blue numbers indicate a SNP that is unlikely to be damaging.
- After finding your SNP of interest, see whether it affects the structure and function of the gene, as shown in Figure 13, above. Specifically, if a SNP has negative red numbers, that SNP is predicted to have a damaging effect on the protein, but if your SNP has blue numbers, it is not predicted to be damaging, and the SNP would be harmless. In other words, the higher the number, the more likely the mutation is to not be damaging.
- Click on red or blue numbers (under "svm profile" or the "svm structure") to learn more about what these values mean.
- Now try to establish a sequence-structure-function relationship for your SNP. First, search for the GENE in OMIM by repeating steps 1–3 above.
- On the OMIM gene page for your gene of interest, under "External Links," click on "Protein" (immediately above "Gene Info," shown in Figures 5 and 6, above). Then click on "UniProt" from the dropdown menu. This will take you to the UniProtKB database, which has additional information on the protein your gene of interest encodes for, as shown in Figure 14, below.
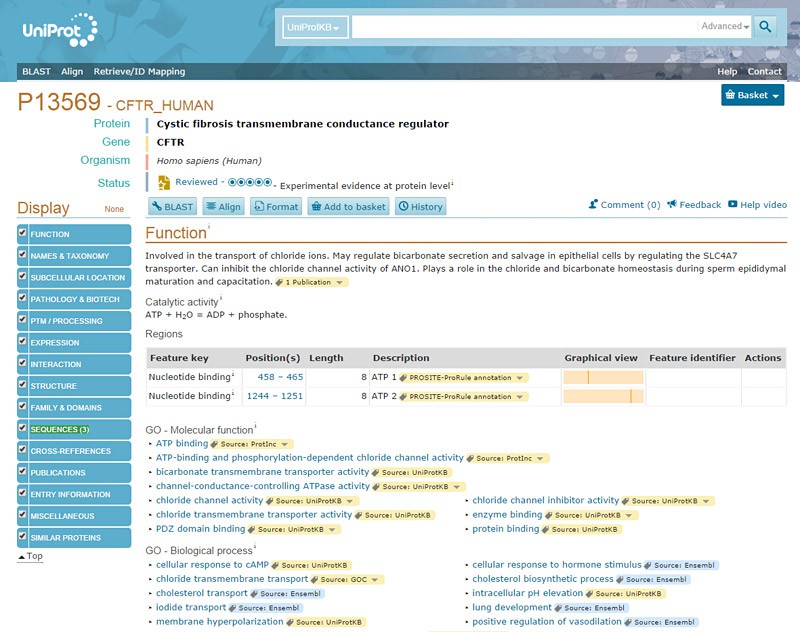 Image Credit: UnitProtKB database / Public Domain
Image Credit: UnitProtKB database / Public DomainScreenshot of the results page for the CFTR gene on the website uniprot.org shows additional information on the CFTR gene. The function of the gene is located near the top of the page and a sidebar filled with links to additional tools and resources can be found on the left side of the page.
Figure 14. The UniProtKB database has additional information on a protein of interest.
- Click on the "Sequences" link on the left side of the UniProtKB webpage, as shown in Figure 15, above, highlighted in green. This will take you to the amino acid sequence for your protein of interest, as shown in Figure 15, below.
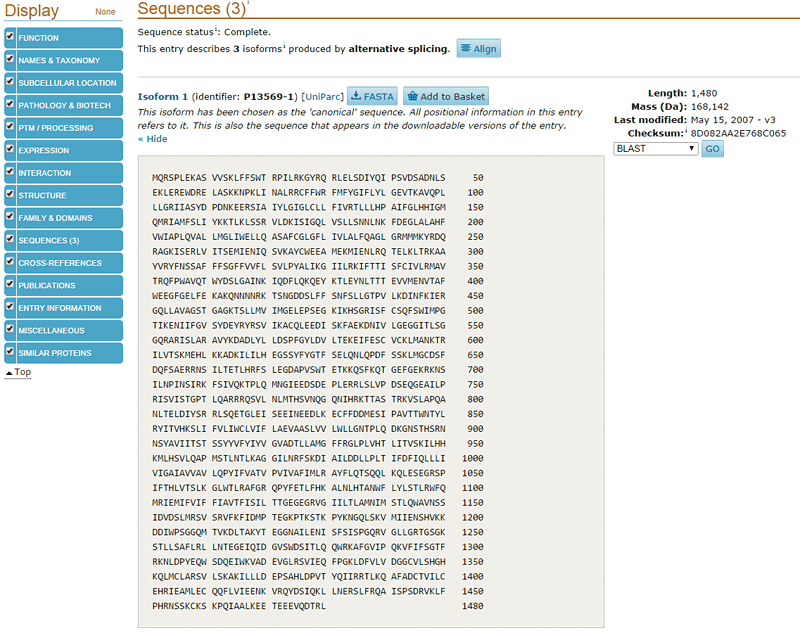 Image Credit: UniProtKB database, National Library of Medicine (NLM) / Public Domain
Image Credit: UniProtKB database, National Library of Medicine (NLM) / Public DomainScreenshot shows a link labeled 'Sequences' within the left side bar on the website snps3d.org. The sequences page has a table at the center of the page that displays the amino acid sequence of the CFTR gene. Information about the amino acid sequence can be found at the top-right of the page.
Figure 15. Clicking on "Sequences" at the top of the UniProtKB webpage for a protein of interest will take you to the amino acid sequence of that protein, as shown here.
- Click on "FASTA" at the top of the "Sequences" section. Select the FASTA protein sequence using your mouse, as shown in Figure 16, below, and copy it.
 Image Credit: UnitProtKB database / Public Domain
Image Credit: UnitProtKB database / Public Domain
Figure 16. The FASTA form of the protein sequence is a convenient form to use when comparing the sequence to other sequences.
- Go to the SMART site as shown in Figure 17. Once there, paste the protein sequence into the "Protein sequence" box and click on "Sequence SMART."
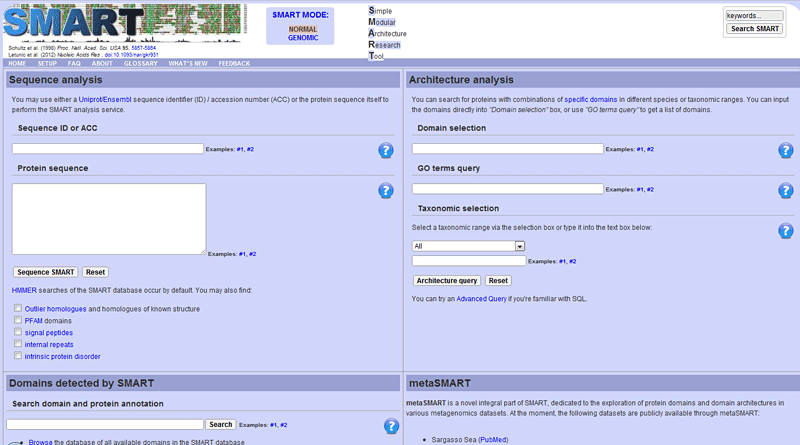 Image Credit: SMART database / Public Domain
Image Credit: SMART database / Public DomainScreenshot of the sequence search page on the website smart.embl-heidelberg.de. A sequence analysis section on the left side of the page has two search boxes that can be used to search by a sequence ID or a protein sequence. Options for architecture analysis can be found on the right side of the webpage. Under architecture analysis there are three fields labeled domain selection, GO terms query and taxonomic selection.
Figure 17. The SMART website has information on the protein domains of different proteins.
- You should see a webpage that shows the domains of your protein of interest, as shown in Figure 18. Rolling your mouse over a domain will show you more information about the protein domain. Find the domain where your mutation is located. Hint: The name you wrote down in step 13, above, includes the sequence location of your SNP of interest. For example, if it said "Met1Val" then the SNP is in amino acid 1.
- For help searching the literature, read the guide to Resources for Finding and Accessing Scientific Papers. You may also find you need some help from someone experienced with genetics or bioinformatics to read and understand the papers.
 Image Credit: SMART database / Public Domain
Image Credit: SMART database / Public DomainScreenshot of the protein sequence results page on the website smart.embl-heidelberg.de. A chart at the top of the page that shows the protein domains where the CFTR gene is found. The page includes a link to InterPro abstract in the table under AAA domain.
Figure 18. This SMART webpage shows the protein domains of the protein sequence that was searched.
- Click on the domain of interest and read the description of the domain and the InterPro abstract, as shown in Figure 18, above, circled in red. Assuming that the SNP results in a mutation in this domain, what could be the biochemical effects of this mutation? How might these effects relate to the disease?
- You can search PubMed for articles on effects of the mutation, as shown in Figure 19. Tip: Try searching for the name of the gene and the SNP, such as "CFTR, Met1Val."
 Image Credit: PubMed, National Library of Medicine / Public Domain
Image Credit: PubMed, National Library of Medicine / Public DomainScreenshot of the PubMed home page at ncbi.nlm.nih.gov/pubmed. The page includes a search bar at the top of the page, and links to tools and resources at the bottom of the page.
Figure 19. PubMed is a searchable database of scientific publications.
Ask an Expert
Global Connections
The United Nations Sustainable Development Goals (UNSDGs) are a blueprint to achieve a better and more sustainable future for all.


Variations
- Variation 1: Environmental Factor - Gene Interaction:
Identify how certain environmental factors may affect genes and their association to diseases by using the Genetic Association Database. NOTE: This database is open-access and allows any user to input data. Use caution while using the data and only select data that has been endorsed by 'Gene Expert' or 'Disease Expert'.
- Click on 'Environmental Factor Gene Interaction' link on the left menu of the website. On the top of the page, click on the link to see a complete list of environmental factors.
- Choose an environmental factor of interest (for e.g., tobacco smoke) by clicking on it.
- You can see entries that describe gene association with specific diseases.
- Are you able to identify any SNPs in this category? Follow links to research more for each category.
- Variation 2: Multi-Species Association / Conserved SNPs:
Using the databases referenced in this project, try to identify gene mutations that are common to multiple species. If a mutation is more frequent across multiple-species and if the mutation can be matched with its phenotype across species, it provides validity to your hypothesis. Highly conserved regions (across species) have an increased likelihood of being functionally important.
- For similar Science Buddies science project ideas that use SNPs and genetics, check out Drugs & Genetics: Why Do Some People Respond to Drugs Differently than Others?, A Prescription for Success: Drugs & Your Genetics, and Trace Your Ancient Ancestry Through DNA.
Careers
If you like this project, you might enjoy exploring these related careers:







